Go可用性(七) 总结: 一张图串联可用性知识点
注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
注:本文所有示例代码都可以在 blog-code 仓库中找到
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营, 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
在前面的几篇文章当中我们聊到了 隔离设计、令牌桶算法、漏桶算法、自适应限流和熔断,可用性的建设远不止这些,这一部分的内容在进阶训练营中也讲了 7 个小时,其他部分如果感兴趣的话推荐购买源课程观看。
由于前面的文章大部分都在讲限流相关的内容,所以我们先看一下不同的限流方式的对比
限流对比
| 类型 | 实现 | 优点 | 缺点 | 文章 |
|---|---|---|---|---|
| 单机限流 | 令牌桶 | 1. 稳定可靠,实现简单,性能高 2. 支持突发流量应对 | 1. 流量不均匀会导致误限制 2. 阈值设置较为困难,需要提前压测 | Go可用性(二) 令牌桶原理及使用 Go可用性(三) 令牌桶的实现 rate/limit |
| 漏桶 | 1. 稳定可靠,实现简单,性能高 | 1. 流量不均匀会导致误限制 2. 阈值设置较为困难,需要提前压测 3. 不支持突发流量 | Go可用性(四) 漏桶算法 | |
| 自适应限流: BBR | 1. 根据服务状态进行动态限流 2. 阈值设置简单,无需提前进行压测 3. 服务扩容无需手动调整阈值 | 1. 需要主动采集相关指标数据(cpu等) 2. 客户端善意限流 3. 应用场景较小 | Go可用性(五) 自适应限流 | |
| 全局限流 | - | 1. 应用场景丰富 2. 流量不均不会误触限流,有全局数据,可以合理进行分配 3. 服务扩容无需手动调整阈值 | 1. 实现较为复杂 2. 配置也较为复杂 | - |
微服务可用性设计总结
接下来我们就一起来串联我们之前讲到的和课程上讲到的一些内容总结一下可用性应该怎么做。
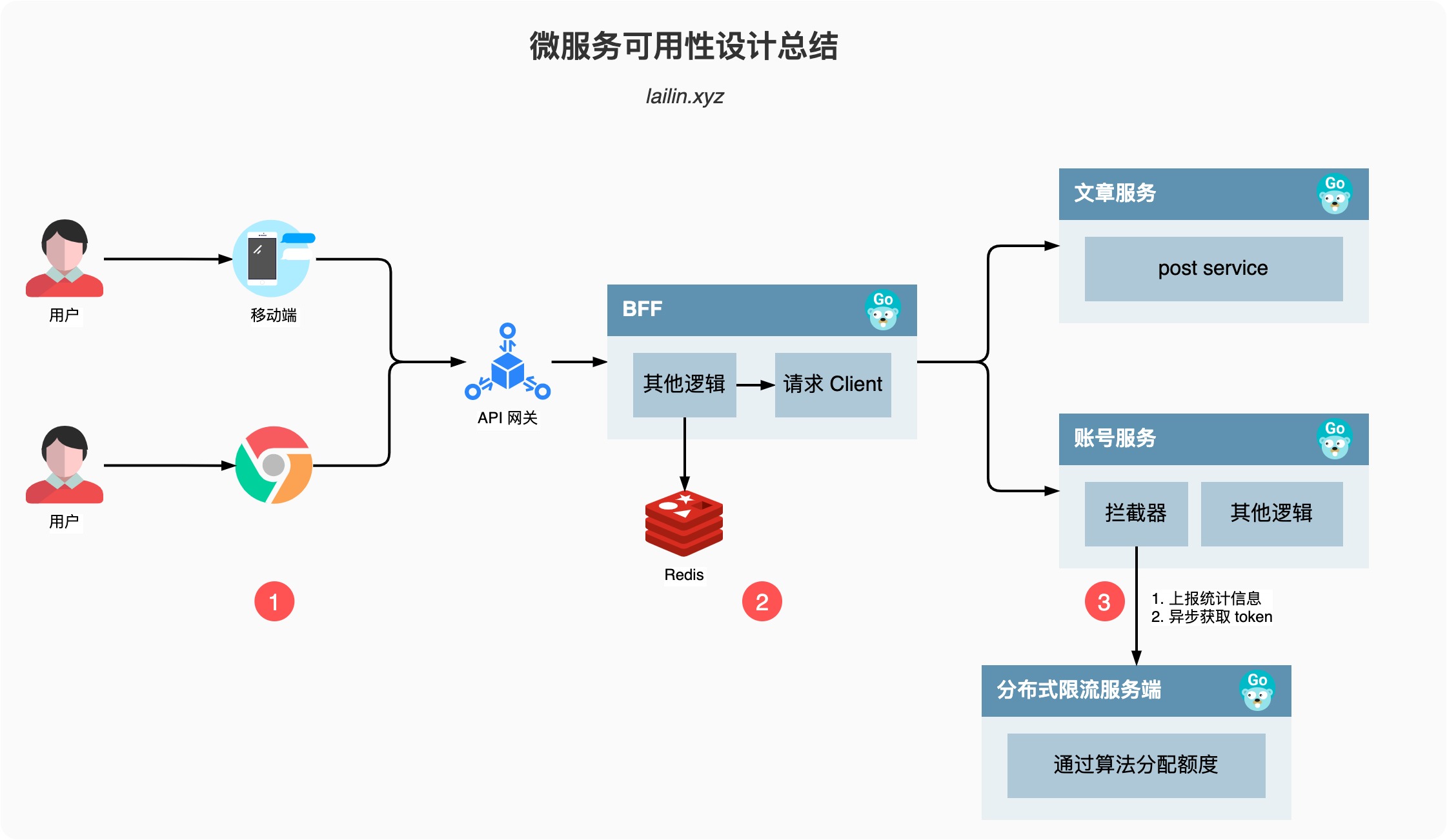
如上图所示,我们从一个简单的用户访问出发,用户访问到我们的服务一般是先通过我们的移动客户端或者是浏览器,然后请求再依次通过 CDN、防火墙、API网关、BFF以及各个后端服务,整条链路还是比较长的。
我们上图其实已经一部分体现了隔离设计,所以后面我就不再提了。
1. 移动客户端/浏览器
客户端是触及用户的第一线,所以这一层做的可用性优化尤为的重要
- 降级: 降级的本质是提供给用户有损服务,所以在触及用户的第一线如何安抚好或者说如何骗过用户的眼睛尤为重要
- 本地缓存,客户端需要有一些本地缓存数据,不仅可以加速用户首屏的加载时间,还可以在后端服务出现故障的时候起到一定的缓冲作用
- 降级数据兼容,服务端有时为了降级会返回一些 mock 数据或者是空数据,这些数据一定要和客户端的对接好,如果没有对接好很容易就会出现异常或者是白屏
- 流控: 在服务出现问题的时候,用户总是会不断的主动尝试重试,如果不加以限制会让我们本就不堪重负的后端服务雪上加霜
- 所以在客户端需要做类似熔断的流控措施,常见的思路有指数级退让,或者是通过服务端的返回获取冷却的时间
2. BFF/Client
BFF 是我们后端服务的桥头堡,当请求来到 BFF 层的时候,BFF 既是服务端,又是客户端,因为它一般需要请求很多其他的后端服务来完成数据的编排,提供客户端想要的数据
- 超时控制:超时控制需要注意的两点是默认值和超时传递
- 默认值,基础库需要有一些默认值,避免客户端用户漏填,错填,举个例子,如果开发填写一个明显过大的值 100s 才超时,这时候我们基础库可以直接抛出错误,或者是警告只有手动忽略才可以正常启动。我之前有一个应用就是因为忘记配置超时时间,依赖的服务 hang 住导致我的服务也无法正常服务了,即使我之前做了缓存也没有用,因为之前的逻辑是只有请求报错才会降级使用缓存数据。
- 超时传递,例如我们上图,假设我们整个请求的超时时间配置的 500ms,BFF 里面首先经过一些逻辑判断消耗了 100ms,然后去请求 redis,我们给 redis 配置的超时时间
max_con是 500ms,这时候就不能用 500ms 作为超时时间,得用min(请求剩余的超时时间,max_con)也就是 400ms 作为我们的超时时间,同样我们请求下游的服务也需要将超时时间携带到 header 信息里面,这样下游服务就可以继承上游的超时时间来进行超时判断。
- 负载均衡:一般我们比较常用的负载均衡策略就是轮训,或者说加个权重,这个比较大的问题就是,我们的服务性能并不是每个实例都一样,受到宿主机的型号,当前机器上服务的数量等等因素的影响,并且由于我们的服务是在随时漂移和变化的,所以我们没有办法为每个实例配上合适的权重。
- 所以我们可以根据一些统计数据,例如 cpu、load 等信息获取当前服务的负载情况,然后根据不同的负载情况进行打分,然后来进行流量的分配,这样就可以将我们的流量比较合理的分配到各个实例上了。
- 重试: 重试一定要注意避免雪崩
- 当我们的服务出现一些错误的时候,我们可以通过重试来解决,例如如果部分实例过载导致请求很慢,我们通过重试,加上面的负载均衡可以将请求发送到正常的实例,这样可以提高我们的 SLA
- 但是需要的注意的是,重试只能在错误发生的地方进行重试,不能级联重试,级联重试很容易造成雪崩,一般的做法就是约定一个 code 只要出现这个 code 我们就知道下游已经尝试过重试了,我们就不要再重试了
- 熔断:一般来说如果只是部分实例出现了问题,我们通过负载均衡阶段+重试一般就可以解决,但如果服务整体出现了问题,作为客户端就需要使用熔断的措施了。
- 熔断常见的有开启,关闭,半开启的状态,例如 hystrix-go 的实现,但是这种方式比较死板,只要触发了熔断就一个请求都无法放过,所以就又学习了 Google SRE 的做法,同构计算概率来进行判断,没有了半开启的状态,开启的时候也不会说是一刀切。
- 降级:当我们请求一些不那么重要的服务出现错误时,我们可以通过降级的方式来返回请求,降级一般在 BFF 层做,可以有效的防止污染其他服务的缓存。常见的讨论有返回 mock 数据,缓存数据,空数据等
3. Server
BFF 其实也是服务端,但是为了流畅的讲解,主要将其作为了客户端的角色。服务端主要的是限流的措施,当流量从 BFF 来到我们的服务之后,我们会使用令牌桶算法尝试获取 token,如果 token 不够就丢弃,如果 token 足够就完成请求逻辑。
我们的 token 是从哪里来的呢?
拦截器会定时的向 Token Server 上报心跳数据,包含了一些统计信息,同时从 Token Server 获取一定数量的 Token,当 Token Server 接受到请求之后会通过最大最小公平分享的算法,根据每个服务实例上报的统计信息进行 Token 的分配。
这个其实就是之前没有讲到的分布式限流的思路,在单个服务实例上又使用了单机限流的算法
总结
到这里我们的可用性相关的知识点就算是告一段落了,前面的文章主要讲解了限流的相关知识点,虽然其他的没有细说,但是这一篇总结也算是都涉及到了,包括隔离设计、限流(单机限流、自适应限流、分布式限流)、超时控制、降级、熔断、负载均衡、重试,如果想要了解细节内容,可以区报名毛大的课程。OK,话不多说,我们下篇文章见。
关注我获取更新



猜你喜欢
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处,禁止全文转载