Go并发编程(二) Go 内存模型
注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营, 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
回顾
在上一篇文章当中我们讲到了使用 goroutine 的一些注意事项,我们先简单回顾一下:
- 请将是否异步调用的选择权交给调用者,不然很有可能大家并不知道你在这个函数里面使用了 goroutine
- 如果你要启动一个 goroutine 请对它负责
- 永远不要启动一个你无法控制它退出,或者你无法知道它何时推出的 goroutine
- 还有上一篇提到的,启动 goroutine 时请加上 panic recovery 机制,避免服务直接不可用
- 造成 goroutine 泄漏的主要原因就是 goroutine 中造成了阻塞,并且没有外部手段控制它退出
- 尽量避免在请求中直接启动 goroutine 来处理问题,而应该通过启动 worker 来进行消费,这样可以避免由于请求量过大,而导致大量创建 goroutine 从而导致 oom,当然如果请求量本身非常小,那当我没说
那我们为什么要这么使用 goroutine 呢?今天我们从原理层面来了解一下 goroutine 的注意事项,本文以 Go 官方博客当中的 https://golang.org/ref/mem 为主干穿插讲解,建议阅读本文前先自行看完一遍原文,会有更多的收获
Go 内存模型
同样我们先来看一段代码,请问下面的代码可能会输出什么?
1 | |
ok,请带着你的答案或者是困惑我们往下走
比较容易想到的结果是:
- 执行顺序: 1 - 2 - 3 - 4, f 先执行, g 后执行, 输出
2 1 - 执行顺序: 3 - 4 - 1 - 2, g 先执行,f 后执行,输出
0 0
就这几种结果么?其实不然,还有可能
- 执行顺序: 1 - 3 - 4 - 2,
f先执行一部分, 然后g执行, 输出0 1
那能不能输出 2 0 呢?
- 先说答案,是有可能的
是不是感觉有点反常识?是不是感觉有点飘忽不定?引用参考文章里面曹大的一句话:
软件(编译器)或硬件(CPU)系统可以根据其对代码的分析结果,一定程度上打乱代码的执行顺序,以达到其不可告人的目的(提高 CPU 利用率)
所以我们在编写并发程序的时候一定要小心,然后回到我们本次的主题 Go 内存模型,就是要解决两个问题,一个是要了解谁先谁后,有个专有名词叫 Happens Before ,另外一个就是了解可见性的问题,我这次读取能不能看到另外一个线程的写入
接下来我们官方的文档《The Go Memory Model》的思路一步一步的了解这些问题,因为官方的文档写的相对比较精炼,所以会比较难懂,我会尝试加入一些我的理解补充说明
忠告
Programs that modify data being simultaneously accessed by multiple goroutines must serialize such access.
To serialize access, protect the data with channel operations or other synchronization primitives such as those in thesyncandsync/atomicpackages.
这个是说如果你的程序存在多个 goroutine 去访问数据的时候,必须序列化的访问,如何保证序列化呢?我们可以采用 channel 或者是 sync 以及 sync/atomic 下面提供的同步语义来保证
Happens Before
序
Within a single goroutine, reads and writes must behave as if they executed in the order specified by the program. That is, compilers and processors may reorder the reads and writes executed within a single goroutine only when the reordering does not change the behavior within that goroutine as defined by the language specification. Because of this reordering, the execution order observed by one goroutine may differ from the order perceived by another. For example, if one goroutine executes a = 1; b = 2;, another might observe the updated value of b before the updated value of a.
这段话就解释了上面我们示例当中为什么会出现 2 0 这种情况。
这段话就是说我们在单个 goroutine 当中的编写的代码会总是按照我们编写代码的顺序来执行
- 当然这个也是符合我们的习惯的
- 当然这并不表示编译器在编译的时候不会对我们的程序进行指令重排
- 而是说只会在不影响语言规范对 goroutine 的行为定义的时候,编译器和 CPU 才会对读取和写入的顺序进行重新排序。
但是正是因为存在这种重排的情况,所以一个 goroutine 监测到的执行顺序和另外一个 goroutine 监测到的有可能不一样。就像我们最上面的这个例子一样,可能我们在 f 执行的顺序是先执行 a = 1 后执行 b = 2 但是在 g 中我们只看到了 b = 2 具体什么情况可能会导致这个呢?不要着急,我们后面还会说到
编译器重排
我们来看参考文章中的一个编译器重排例子
1 | |
在这段代码中,X = 1 在 for 循环内部被重复赋值了 100 次,这完全没有必要,于是聪明的编译器就会帮助我们优化成下面的样子
1 | |
完美,在单个 goroutine 中并不会改变程序的执行,这时候同样会输出 100 次 1 ,并且减少了 100 次赋值操作。
但是,如果与此同时我们存在一个另外一个 goroutine 干了另外一个事情 X = 0 那么,这个输出就变的不可预知了,就有可能是 1001111101… 这种,所以回到刚开始的忠告:这个是说如果你的程序存在多个 goroutine 去访问数据的时候,必须序列化的访问
happens before 定义
To specify the requirements of reads and writes, we define happens before, a partial order on the execution of memory operations in a Go program. If event
e1happens before evente2, then we say thate2happens aftere1. Also, ife1does not happen beforee2and does not happen aftere2, then we say thate1ande2happen concurrently.
这是 Happens Before 的定义,如果 e1 发生在 e2 之前,那么我们就说 e2 发生在 e1 之后,如果 e1 既不在 e2 前,也不在 e2 之后,那我们就说这俩是并发的
Within a single goroutine, the happens-before order is the order expressed by the program.
这就是我们前面提到的,在单个 goroutine 当中,事件发生的顺序,就是程序所表达的顺序
A read r of a variable
vis allowed to observe a writewtovif both of the following hold:
- r does not happen before
w.- There is no other write
w'tovthat happens after w but beforer.
假设我们现在有一个变量 v,然后只要满足下面的两个条件,那么读取操作 r 就可以对这个变量 v 的写入操作 w 进行监测
- 读取操作
r发生在写入操作w之后 - 并且在
w之后,r之前没有其他对v的写入操作w'
注意这里说的只是读取操作 r 可以对 w 进行监测,但是能不能读到呢,可能可以也可能不行
To guarantee that a read
rof a variablevobserves a particular writewtov, ensure thatwis the only writeris allowed to observe. That is,ris guaranteed to observewif both of the following hold:
whappens beforer.- Any other write to the shared variable
veither happens beforewor afterr.
为确保对变量 v 的读取操作 r 能够监测到特定的对 v 进行写入的操作 w,需确保 w 是唯一允许被 r 监测的写入操作。也就是说,若以下条件均成立,则 r 能保证监测到 w:
w发生在r之前。- 对共享变量
v的其它任何写入操作都只能发生在w之前或r之后。
这对条件的要求比第一个条件更强,它需要确保没有其它写入操作与 w 或 r 并发。
在单个 goroutine 当中这两个条件是等价的,因为单个 goroutine 中不存在并发,在多个 goroutine 中就必须使用同步语义来确保顺序,这样才能到保证能够监测到预期的写入
单个 goroutine 的情况:
我们可以发现在单个 goroutine 当中,读取操作 r 总是可以读取到上一次 w 写入的值的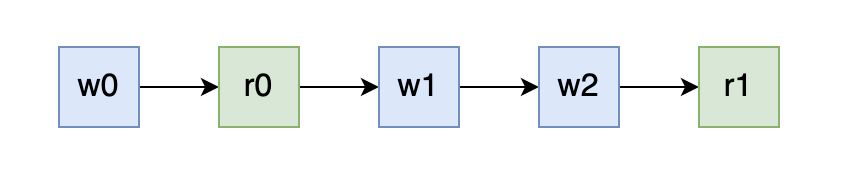
多个 goroutine 的情况:
但是存在多个 goroutine 的时候这个就不一定了,r0 读到的是 哪一次写入的值呢?如果看图的话像是 w4 的,但其实不一定,因为图中的两个 goroutine 所表达的时间维度可能是不一致的,所以 r0 可能读到的是 w0 w3 w4 甚至是 w5 的结果,当然按照我们前面说的理论,读到的不可能是 w1 的结果的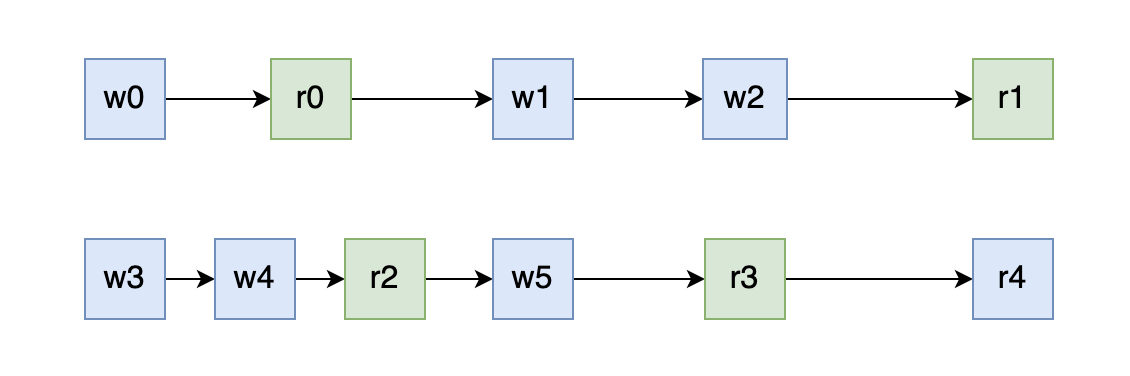
添加一些同步点
如下图所示我们通过 sync 包中的一些同步语义或者是 channel 为多个 goroutine 加入了 同步点,那么这个时候对于 r1 而言,他就是晚于 w4 并且早于 w1 和 w5 执行的,所以它读取到的是写入操作是可以确定的,是 w4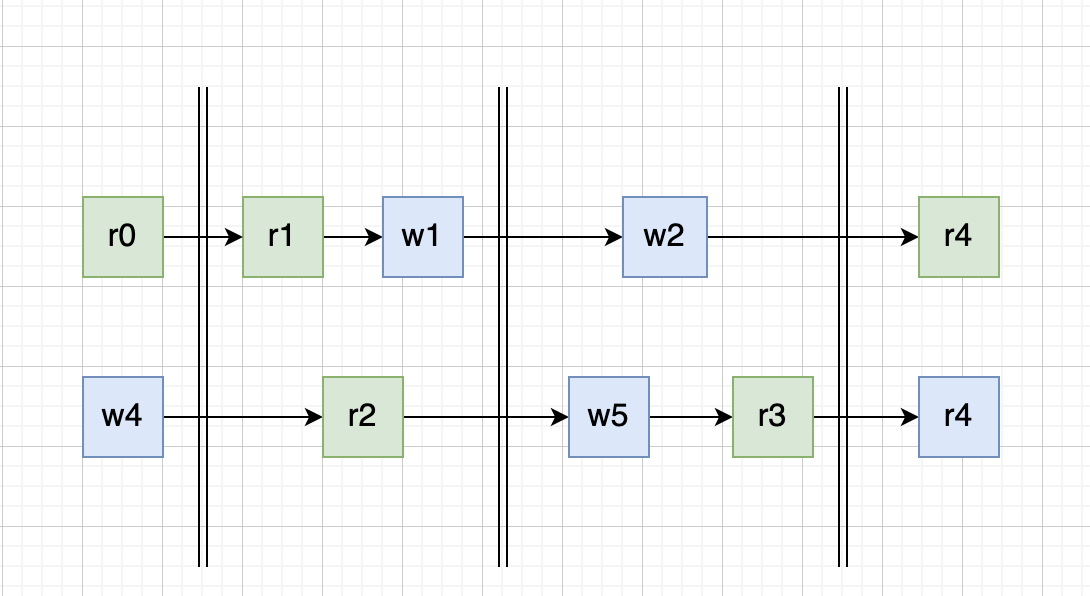
The initialization of variable
vwith the zero value forv‘s type behaves as a write in the memory model.
以变量 v 所属类型的零值来对 v 进行初始化,其表现如同在内存模型中进行的写入操作。
机器字
Reads and writes of values larger than a single machine word behave as multiple machine-word-sized operations in an unspecified order.
对大于单个机器字的值进行读取和写入,其表现如同以不确定的顺序对多个机器字大小的值进行操作。要理解这个我们首先要理解什么是机器字。
我们现在常见的还有 32 位系统和 64 位的系统,cpu 在执行一条指令的时候对于单个机器字长的的数据的写入可以保证是原子的,对于 32 位的就是 4 个字节,对于 64 位的就是 8 个字节,对于在 32 位情况下去写入一个 8 字节的数据时就需要执行两次写入操作,这两次操作之间就没有原子性,那就可能出现先写入后半部分的数据再写入前半部分,或者是写入了一半数据然后写入失败的情况。
也就是说虽然有时候我们看着仅仅只做了一次写入但是还是会有并发问题,因为它本身不是原子的
同步
初始化
Program initialization runs in a single goroutine, but that goroutine may create other goroutines, which run concurrently.
If a packagepimports packageq, the completion ofq‘sinitfunctions happens before the start of any ofp‘s.
The start of the functionmain.mainhappens after allinitfunctions have finished.
- 程序的初始化运行在单个 goroutine 中,但该 goroutine 可能会创建其它并发运行的 goroutine
- 若包 p 导入了包 q,则 q 的 init 函数会在 p 的任何函数启动前完成。
- 函数 main.main 会在所有的 init 函数结束后启动。注意: 在实际的应用代码中不要隐式的依赖这个启动顺序
goroutine 的创建
The
gostatement that starts a new goroutine happens before the goroutine’s execution begins.
go 语句会在 goroutine 开始执行前启动它
goroutine 的销毁
The exit of a goroutine is not guaranteed to happen before any event in the program。
goroutine 无法确保在程序中的任何事件发生之前退出
注意 《The Go Memory Model》原文中还有关于 channel, 锁相关的阐述,因为篇幅原因在本文中就不多讲了,后面我们还有单独的文章详细讲 channel 和 锁 相关的使用,在强调一遍,原文一定要多看几遍
内存重排
在上面我们讲到了编译器重排,以及在最开始的例子中我们提到了可能会存在 2 0 这个答案,接下来我们就来看看为什么。如果大家购买电脑的时候有去对比 cpu 的话应该可以看到,每个 cpu 都会写一下一级缓存,二级缓存,三级缓存的大小,这个缓存就是这里的一个关键点,一般而言,越往下缓存的大小越大速度越慢,这是 cpu 为了提高执行速度做的缓存体系,就像我们平时在应用当中引入 redis 作为缓存类似,都是为了加速。同时这就会带来一些数据不一致的问题。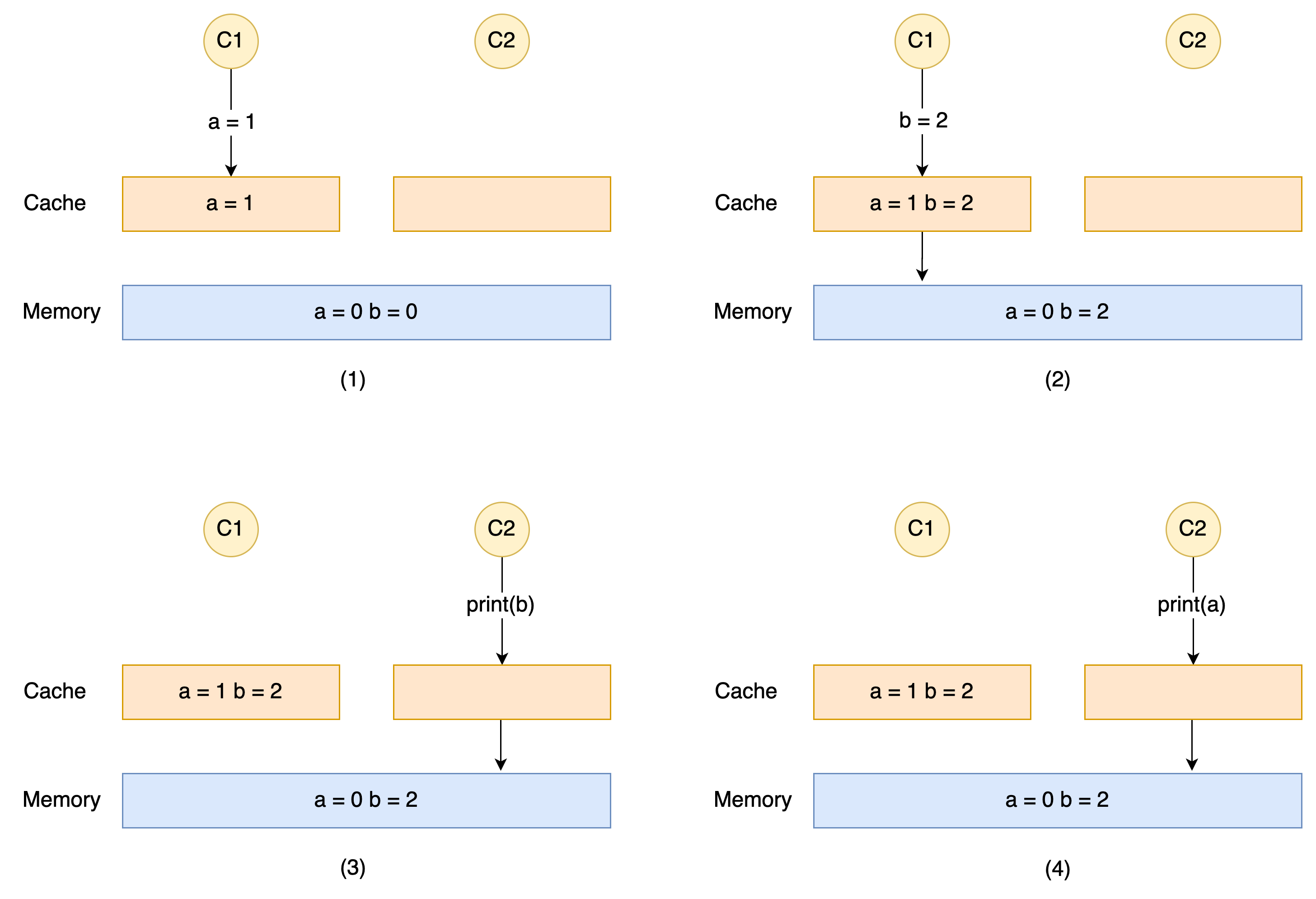
如上图所示:
- C1 执行 a = 1 将 store buffer 中 a 的值写为 1
- C1 执行 b = 2 将 store buffer 中 b 的值写为 2, 然后由于某种原因将 b 的值写入到了内存中
- C2 去读取 b 的值,发现缓存中没有,就去内存中读,这时候 print 出来 2
- C2 去读取 a 的值,发现缓存中没有,就去内存中读,这时候 print 出来 0
了解到这里之后可能会有一些疑问,既然会存在这种不确定性,我们有没有什么办法去保证一致呢?CPU 的一致性具体又是怎么回事?
保证一致从程序上来讲我们必须使用同步语义的工具确保一致,如果深入到底层的话就是使用 cpu 提供的内存屏障命令,保证所有对内存的操作都必须要“扩散”到 memory 之后才能继续执行其他对 memory 的操作。
CPU 一致性的原理建议看一下 MSI(E)协议的实现,我在参考文献中列出的最后两篇文章讲的已经比较通俗易懂了,在本文就不再叙述
总结
- Go 的并发编程非常的简单,只需要使用 go func 就能启动一个新的协程,但是并发编程本身就是很容易出现 bug 的,而且由于并发导致的 bug 还不太容易发现,所以我们在写并发逻辑的时候一定要非常小心,用官方的一句话就是使用显示的同步
- 本文更多是抛砖引玉这里面提到了很多有意思的名词都值得好好研究
参考文献
- https://golang.org/ref/mem 官方文档一定要多读几遍
- https://go-zh.org/ref/mem 官方文档的中文翻译,英文比较吃力可以看这篇
- https://qcrao.com/2019/06/17/cch-says-memory-reorder/
- https://cch123.github.io/ooo/
- https://www.cs.utexas.edu/~bornholt/post/memory-models.html
- https://baike.baidu.com/item/%E6%9C%BA%E5%99%A8%E5%AD%97%E9%95%BF
- https://zh.wikipedia.org/wiki/%E5%AD%97_(%E8%AE%A1%E7%AE%97%E6%9C%BA)
- https://zhuanlan.zhihu.com/p/65245043
- https://zhuanlan.zhihu.com/p/94811032
关注我获取更新



猜你喜欢
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处,禁止全文转载