注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营 , 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
序 在前面两篇文章当中我们学习了令牌桶算法的使用和实现,今天我们就一起来看一看另外一种常见的限流算法,漏桶算法
漏桶算法 原理 漏桶算法(Leaky Bucket) 是网络世界中流量整形(Traffic Shaping)或速率限制(Rate Limiting)时经常使用的一种算法,它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。 — 百度百科
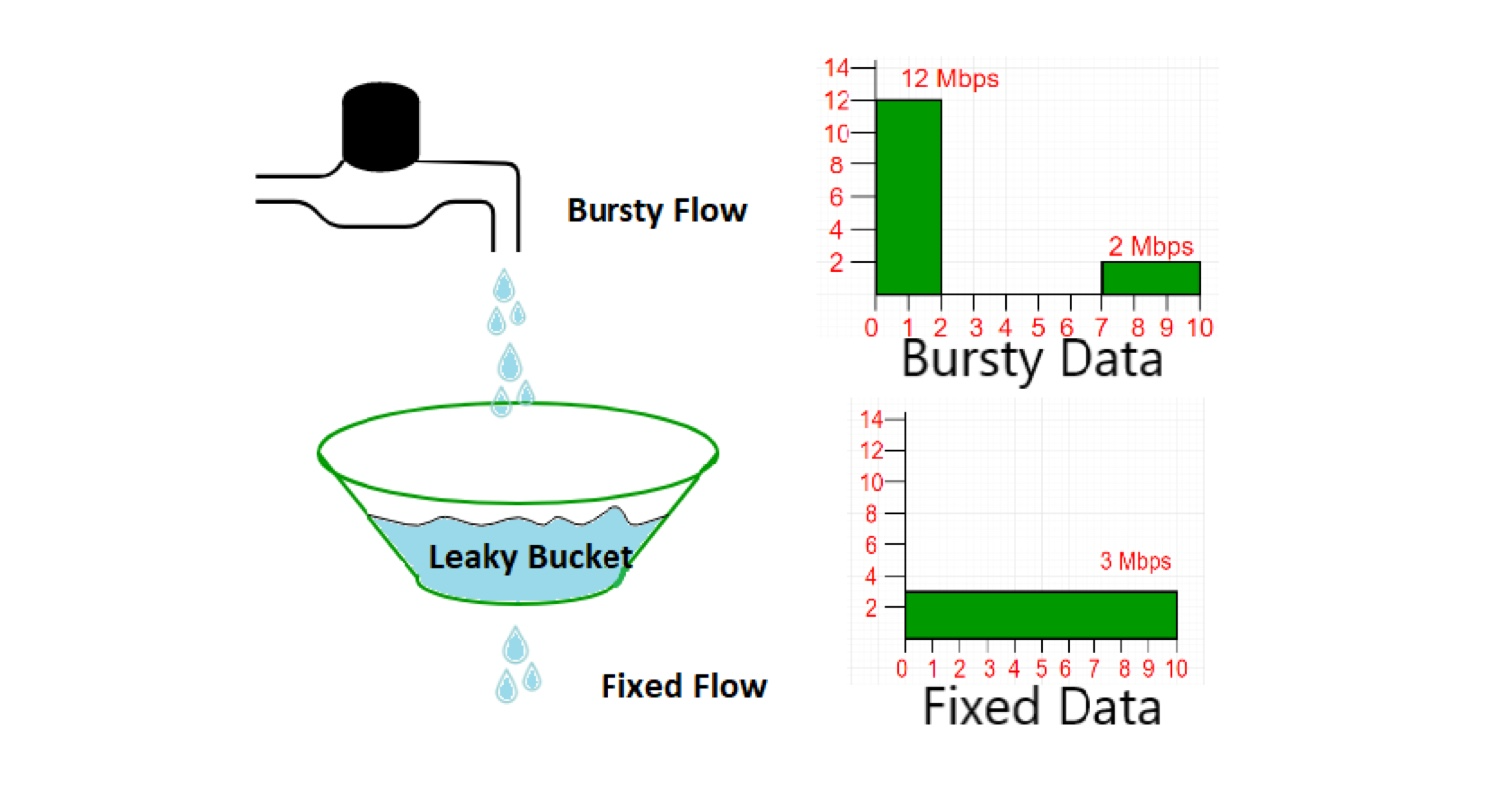
漏桶算法其实非常形象,如下图所示可以理解为一个漏水的桶,当有突发流量来临的时候,会先到桶里面,桶下有一个洞,可以以固定的速率向外流水,如果水的从桶中外溢了出来,那么这个请求就会被拒绝掉。具体的表现就会向下图右侧的图表一样,突发流量就被整形成了一个平滑的流量。
漏桶算法的主要作用就是避免出现有的时候流量很高,有的时候又很低,导致系统出现旱的旱死,涝的涝死的这种情况。
Go 中比较常用的漏桶算法的实现就是来自 uber 的 ratelimit ,下面我们就会看一下这个库的使用方式和源码
API 1 2 3 4 5 6 7 8 type Clocktype Limiterfunc New (rate int , opts ...Option) Limiter func NewUnlimited () Limiter type Optionfunc Per (per time.Duration) Option func WithClock (clock Clock) Option func WithSlack (slack int ) Option
Clock 是一个接口,计时器的最小实现,有两个方法,分别是当前的时间和睡眠
1 2 3 4 type Clock interface {
Limiter 也是一个接口,只有一个 Take 方法,执行这个方法的时候如果触发了 rps 限制则会阻塞住
1 2 3 4 type Limiter interface {
NewLimter 和 NewUnlimited 会分别初始化一个无锁的限速器和没有任何限制的限速器
Option 是在初始化的时候的额外参数,这种使用姿势在之前 Go 工程化的文章《Go 工程化(六) 配置管理》 当中有讲到,这里我们就不再赘述了
Option 有三个方法
Per 可以修改时间单位,默认是秒所以我们默认限制的是 rps,如果改成分钟那么就是 rpm 了WithClock 可以修改时钟,这个用于在测试的时候可以 mock 掉不使用真实的时间WithSlack 用于修改松弛时间,也就是可以允许的突发流量的大小,默认是 Pre / 10 ,这个后面会讲到案例: 10 行代码实现一个基于漏桶算法的 ip 限流中间件 案例我们使用和令牌桶类似的案例
1 2 3 4 5 6 7 8 9 10 11 12 13 func NewLimiter (rps int ) gin .HandlerFunc return func (c *gin.Context) "now: %s\n" , now)
使用上也是比较简单的
1 2 3 4 5 6 7 8 9 func main () 3 ))"ping" , func (c *gin.Context) "pong" )":8080" )
我们用 go-stress-testing 进行压测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 go -stress-testing-linux -c 100 -u http:1 s│ 13 │ 13 │ 0 │ 233.55 │ 676.10 │ 5.82 │ 85.64 │ 52 │ 51 │200 :13 2 s│ 16 │ 16 │ 0 │ 62.25 │ 1675.17 │ 5.82 │ 321.30 │ 64 │ 31 │200 :16 3 s│ 19 │ 19 │ 0 │ 31.24 │ 2673.94 │ 5.82 │ 640.20 │ 76 │ 25 │200 :19 3 s│ 20 │ 20 │ 0 │ 26.37 │ 3006.49 │ 5.82 │ 758.51 │ 80 │ 26 │200 :20 20 20 总请求时间: 3.011 秒 successNum: 20 failureNum: 0
查看结果发现为什么第一秒的时候完成了 13 个请求,不是限制的 3rps 么?不要慌,我们看看它的实现就知道了
实现 这个库有基于互斥锁的实现和基于 CAS 的无锁实现,默认使用的是无锁实现版本,所以我们主要看无锁实现的源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 type state struct {type atomicLimiter struct {56 ]byte
atomicLimiter 结构体
state 是一个状态的指针,用于存储上一次的执行的时间,以及需要 sleep 的时间padding 是一个无意义的填充数据,为了提高性能,避免 cpu 缓存的 false sharing之前在讲 Go 并发编程(二) Go 内存模型 的时候有讲到,为了能够最大限度的利用 CPU 的能力,会做很多丧心病狂的优化,其中一种就是 cpu cache cpu cache 一般是以 cache line 为单位的,在 64 位的机器上一般是 64 字节 所以如果我们高频并发访问的数据小于 64 字节的时候就可能会和其他数据一起缓存,其他数据如果出现改变就会导致 cpu 认为缓存失效,这就是 false sharing 所以在这里为了尽可能提高性能,填充了 56 字节的无意义数据,因为 state 是一个指针占用了 8 个字节,所以 64 - 8 = 56 剩下三个字段和 Option 中的三个方法意义对应perRequest 就是单位,默认是秒maxSlack 松弛时间,也就是可以允许的突发流量的大小,默认是 Pre / 10 ,这个后面会讲到clock 时钟,这个用于在测试的时候可以 mock 掉不使用真实的时间 接下来看看最主要的 Take 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 func (t *atomicLimiter) Take () time .Time var (bool for !taken {if oldState.last.IsZero() {continue if newState.sleepFor < t.maxSlack {if newState.sleepFor > 0 {0 return newState.last
总结 今天学习了漏桶的实现原理以及使用方式,漏桶和令牌桶的最大的区别就是,令牌桶是支持突发流量的,但是漏桶是不支持的。但是 uber 的这个库通过引入弹性时间的方式也让漏桶算法有了类似令牌桶能够应对部分突发流量的能力,并且实现上还非常的简单,值得学习。
多看看好的轮子的实现总会学到一些新姿势,今天就学到了使用 padding 填充来避免 false sharing 提高性能的操作
参考文献 Go 进阶训练营-极客时间 “带你快速了解:限流中的漏桶和令牌桶算法” ratelimit · pkg.go.dev ratelimit/limiter_atomic.go at main · uber-go/ratelimit (github.com) 漏桶算法_百度百科 (baidu.com) 利用 CPU cache 特性优化 Go 程序 关注我获取更新 猜你喜欢