Go工程化(九) 项目重构实践
注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营, 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
序
3 月进度: 06/15 3 月开始会尝试爆更模式,争取做到两天更新一篇文章,如果感兴趣可以拉到文章最下方获取关注方式。
这是《Go 工程化》系列的最后一篇文章了,其实在 Go 并发编程完结的时候我想的工程化这一章节不要写这么多,以听课笔记为主就可以了,但是最后还是展开讲了很多内容,与其说是为了做笔记或者是写文章,不如说是为了整理一下过去几年我的一些微不足道的经验,结合毛老师课上讲的内容与自己的情况重新对已有的知识进行了一遍梳理。
在前面的八篇文章当中我们讲到了,项目结构、依赖注入,API 设计、配置管理、包管理、单元测试,基本上还是将工程化当中的大部分东西都讲到了,不求尽善尽美,但求对你有所帮助,我们今天就来结合前面文章中提到的各种知识来看一下如何将一个老的项目迁移到新的项目结构当中来,这里面的坑也非常的多。
这篇文章是从之前重构的一个真实项目映射而来,里面讲到的坑基本上在迁移重构的过程中都趟了不止一次。
迁移前
目录结构
1 | |
这是我们最开始的目录结构,这个结构是仿照 rails 框架设计而来的,这个结构在很长一段时间都是挺好用的,我先大概解释一下每个目录的含义
- app: 应用逻辑相关的代码都在这里
- controller: 控制器层,主要负责路由
- lib: 一些工具库函数
- middleware: 路由中间件
- router: 路由注册
- model: 由于我们使用的是充血模型,所以这一层的内容比较多,包含了领域对象,业务逻辑,数据存储等都在这里
- cmd: 二进制文件目录
- cron: 定时任务
- server: http server 服务
- db: migration 目录
- mock: gomock 生成的文件
- test: 测试工具库
- third_party: 第三方文件
调用关系如下图所示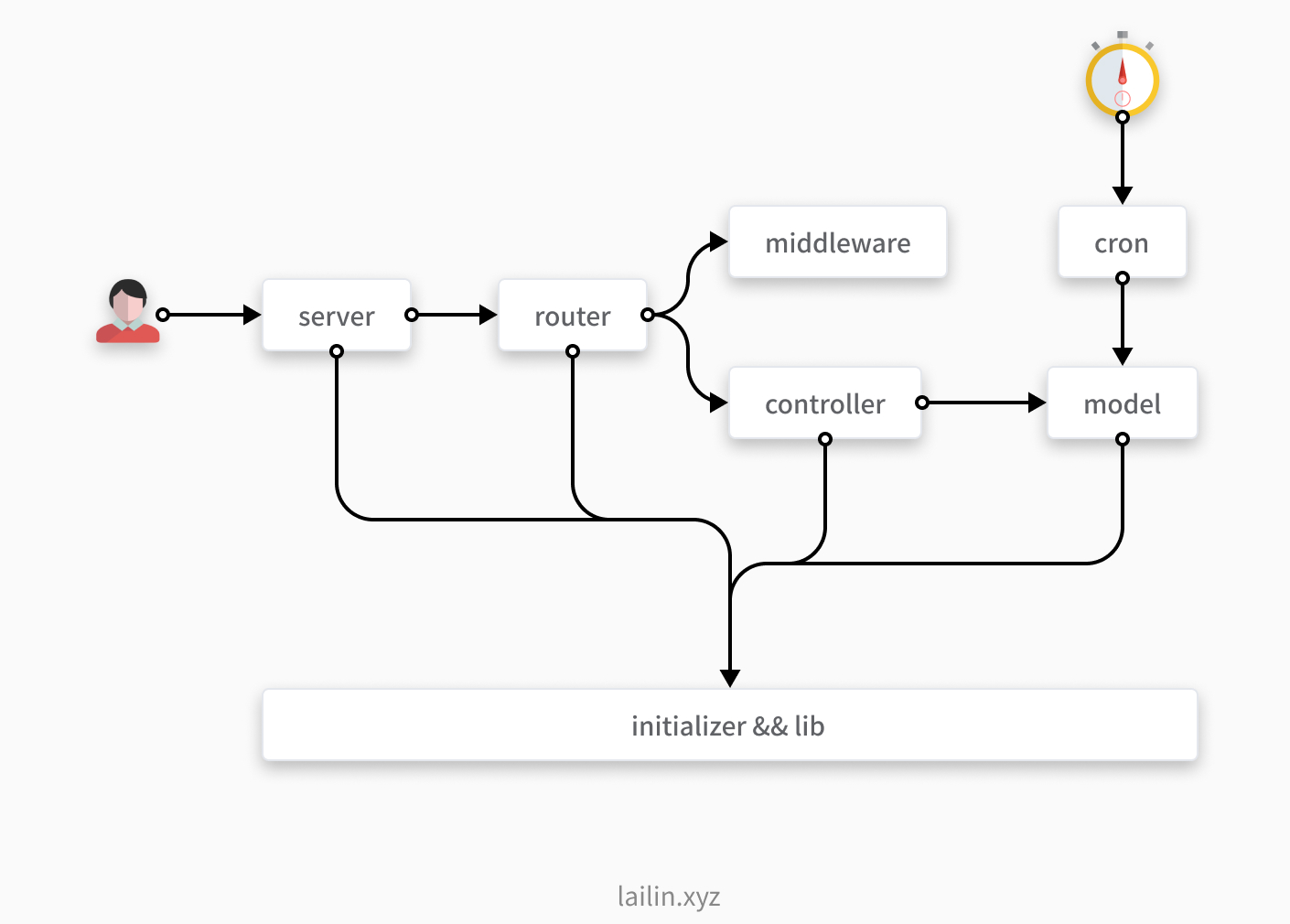
存在的问题
其实在报名参加 Go 进阶训练营 之前我就因为在提高这个项目的单元测试覆盖率的时候发现了很多问题,当时我用了各种操作,非常难受的将单元测试覆盖率写到 85% 左右的时候就写不上去了,因为我们的项目的历史包袱太严重了,很多代码写的基本就不可测试,想要提高测试覆盖率也就无从谈起了。
- cmd
- 我们之前在这一层当中最大的问题就是我们手写了大量启动代码,全手动依赖注入,还有一些隐式的依赖,这就导致在项目后期的时候启动的代码已经非常长了,而且很容易遗漏依赖关系的处理,建议如果不是特别小的项目还是使用 wire 比较香。
- initializer
- 我们之前所有的初始化都在这个包内完成,这个不是太大的问题,但是要命的是这里面有大量的全局变量,各种各样,过多的全局变量导致我们的单元测试非常难写。
- model
- 这一层的事情特别多,业务逻辑,领域对象,持久化存储等都在这一层完成,这就导致了后面我们 model 层的代码特别多,变成了一团乱麻,真的是剪不断理还乱,慢慢的这一层的逻辑我自己都理不清了。
- 这一层的代码耦合也很严重,无论是什么定时任务还是消息队列还是 server 的代码都放到了这里,导致出现了很多坑,举个例子,可能我有一个函数是
GetArticles这个函数最开始是为了 api 接口返回一些简要的列表数据,只需要查询一张表,返回速度非常快,但是我定时任务有一个地方也需要这个函数,然后我一看,真好这里已经有这个函数了我们就直接复用,但是数据内容不满足需求,我们就直接在这个函数当中加逻辑,然后需求满足了,过一段时间我们突然要求所有的接口必须要在 500ms 以内,结果发现坑来了,很多地方依赖这个函数,看 APM,就这一个函数的查询就需要耗费超过 500ms 🤣
- controller
- 这一层主要做参数的处理还有部分业务逻辑,我们的 Controller 层和 model 层的界定比较模糊,有的主要业务逻辑放到了 model 有的有部分业务逻辑又放到了 Controller 了,到后面就是一点一点的找问题
- 错误处理
- 我们之前在项目内统一了错误码,但是存在两个问题
- 一个是要么处处 wrap,要么忘记 wrap 没有一个统一准则,这就导致要么错误堆栈长的没法看,要么就没有太多的错误信息没法排查
- 另一个是我们之前在 Controller 层跑业务错误代码,这就导致了很多时候想要返回一些细节的错误信息就无能为力,即使在 model 层抛了也会被 Controller 层吞掉
- 接口文档
- 这也是一个很大的痛点,之前想了很多方式都不能很好的解决,毛老师给出这个方案后,我没多久就用上了非常爽。
- 之前我们的文档分布五花八门,最开始使用 gin swagger 通过写注释的方式来生成相关接口文档,说实话可以用但是比较难用,因为这个注释其实和代码逻辑是两套东西,相当于写一遍代码再写一遍注释,慢慢的就没有人写了,或者还有写的是错误的。最麻烦的是在方案设计阶段我们不会直接写代码注释,所以测试同学在写测试方案的时候会比较麻烦,也不符合我们后续技术方案评审的要求所以后面也就废弃了
- 后面我们写到内部的文档平台上,还不如之前的 swagger,虽然解决了方案阶段没接口文档的问题,但是接口文档总是在变化当中的,特别是在开发的时候,这就让前后端对接联调,以及测试同学测试的非常难受,特别是经常会出现和前端同学沟通好了但是忘记和测试说的情况。
迁移
迁移要三思,处处都是坑, 重构要小心,TDD 大法好
迁移后目录结构
为了能够更加直观,我们先来复习一下之前提到过的项目目录结构看一下迁移前后有哪些不同
1 | |
具体每个文件夹的含义就不再赘述,如果不太清楚可以查看 Go 工程化(二) 项目目录结构
我们看一下新的目录结构的调用链路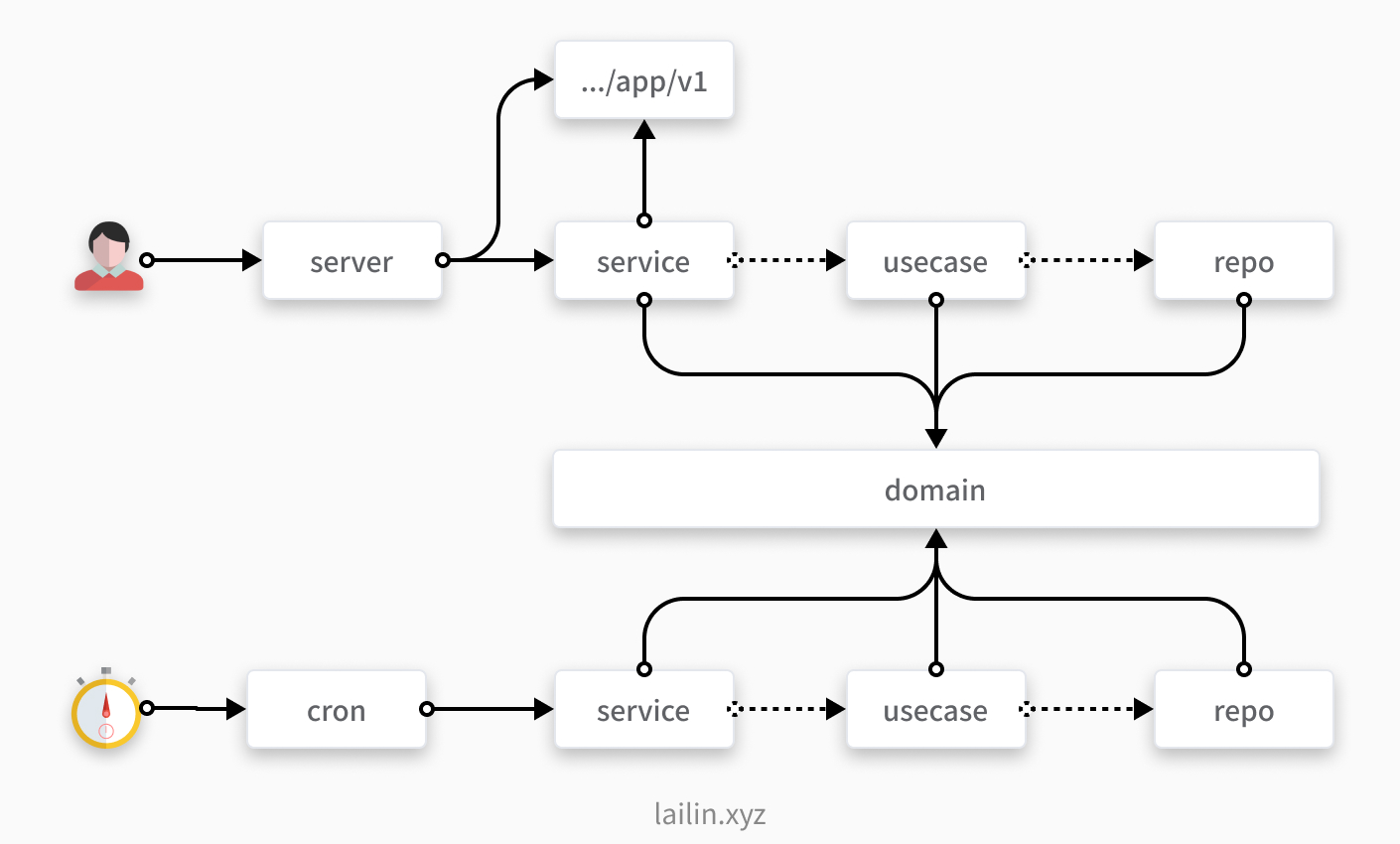
注意,在这里 service 和 usecase 实际调用的都是 domain 中的接口,只是 usecase 和 repo 实现这些接口而已,所以我们这里用虚线画出来
迁移重构原则
接下来我会从各个模块来阐述我在重构这个项目的时候是怎么做的,每个模块都有每个模块自己的坑。开始之前呢我们先来看一下几个总的原则:
- 结构简单的应用优先
- 有充分的单元测试的应用优先
- 先写测试,测试需要在新老代码同时通过
api
api 当中主要写的就是 proto 文件,这个 proto 文件替代了我们在之前的 router 以及部分 controller 中的逻辑,定义了 proto 文件之后,生成的代码当中主要要完成的就是,路由的注册,参数绑定,返回值结构填充。
背景
先补充一下背景,我们之前的项目采用的是 gin 作为路由框架,返回值采用下面这种统一的结构
1 | |
在 api 层的路由注册,参数绑定,返回值结构填充我们都使用工具进行统一处理,详细介绍可以看之前的文章: Go 工程化(五) API 设计下: 基于 protobuf 自动生成 gin 代码
简单案例
先来看一个基本的例子
1 | |
成功的例子千篇一律,路上的坑各不相同,我们来看一下几个典型的坑(问题),以及该如何解决
Q1: Get 请求参数如何进行绑定,默认无法修改 struct tag
这个稳定同样适用于参数校验,原来 gin 参数校验可以在 struct 上加 tag 解决,这个有两种解决方案,一种是使用 protoc-go-inject-tag 加注释解决,另外一种是使用 gogo/protobuf 支持添加 option 的方式来添加 tag,目前我采用的是第一种
只需要在定义 message 的时候添加注释 // @inject_tag: 后面是具体的 tag
1 | |
然后我们在生成好对应的 go 文件之后执行一下 protoc-go-inject-tag -input=filepath 就可以了
Q2: 返回值是一个数组
举个例子,我们之前可能有一个 get: /article/tags 的接口,由于一篇文章当中的标签不会很多,所以我们没有做分页,返回数据的时候直接在 data 里面塞了一个数组,然后我们迁移的时候就麻烦了 o(╥﹏╥)o
因为在 protobuf 的 rpc 方法定义当中,只能返回一个结构体,无法返回一个数组结构,但是我们做重构的时候又不想有 api 的破坏性变更,因为这项所有的依赖方都需要进行修改成本太大了,那我们如何兼容呢?
我的解决方案是先生成对应的 go 结构体,然后在同一个包内创建一个 xx_type.pb.go 里面实现 json 的解析接口,让我们虽然定义的是一个结构体,但是返回接口数据的时候返回的是一个数组
举个例子,下面是我定义的 pb
1 | |
然后生成了 v1.pb.go ,我创建了一个 v1_type.pb.go
1 | |
当然后续最好还是修改一下,但是重构的时候还是建议不要做破坏性的变动
Q3: 返回值当中包含时间
除了数组之外,返回值当中包含时间也是挺麻烦的一件事情,首先 pb 的基础类型里面没有时间类型,然后 google 官方的库当中有一个 timestamp 包,可以使用,但是使用的时候就会发现,在 json 序列话的时候不是一个时间字段,而是一个对象值,和我们之前直接使用 time.Time 的行为不一致。
我的做法是仿照 google 的包自己搞一个然后实现 json 的相关方法,让 json 序列化的时候的行为和 time.Time 保持一致
首先定义 timestamp.proto
1 | |
和上面一样,创建一个 timestamp_type.pb.go ,除了实现 json 的接口以外还实现了两个转换方法,用于 service 层调用
1 | |
domain
domain 这一层主要是包含 do 对象的定义,以及 usecase 和 repo 层的接口定义,由于我们现在使用的 gorm 所以,也会在这里给 do 对象加上一些 tag 用于标志索引,关联关系等。
domain example
1 | |
这一层的坑稍微少一些,主要是接口定义的相关事情
小技巧: 批量 mock 接口
使用最新的项目结构我们会在 domain 中创建大量接口,之前在 Go 工程化(八) 单元测试 中我们提到了,在每一层的单元测试的时候,我们都会把依赖的接口用 gomock 给 mock 掉,让测试尽量轻量级一些,为了简化 gomock 的创建,我们可以在 makefile 当中写一个 shell 脚本,找出含有 interface 定义的文件,然后我们用 gomock 生成对应的 mock 文件
1 | |
service
新的 service 层的主要左右就是 dto 数据和 do 数据的相互转换,它实现了 v1 包中的相关接口,service 的代码比较简单,我们直接看一个例子
service example
注意,我们在迁移 service、usecase、repo 的时候,都应该先写对应的单元测试,本文当中由于篇幅原因我就没有再列了,感兴趣可以查看上一篇文章 Go 工程化(八) 单元测试 对应章节的内容
1 | |
小技巧: copier 减少重复的复制粘贴操作
在上面的例子我们可以看到,我们的数据转换是手动写的,这种方法不是不行,但是示例当中的字段比较少,如果字段多了起来,并且还有各种数组类型的存在的时候,数据转换的这部分代码写的就会比较难受了,如果你的应用和我的一样对性能的要求不是很高的话可以试试下面这种方式。
我最开始是用了 jinzhu 大佬的 copier 包来做的数据转换,但是这个包比较局限,它主要是在两个结构的之间的字段名以及类型相同的时候有用,向出现我们上面在 api 部分讲的那种骚操作就不适用了,并且我还出现过由于两边字段的大小写不一致导致最后有一个字段没有复制成功导致的问题(所以用这个一定要写对应的单元测试)。
所以结合我们之前的操作,我自己手动写了一个 copier 函数签名一样,实现非常简单,当然性能不太好,但是如果对性能要求不高的话也能用.
如下所示,就是用 json 来回倒腾两次就行了
1 | |
如果使用这个函数的话,我们上面的代码就可以改成
1 | |
usecase
这一层主要是业务逻辑,业务逻辑相关代码都应该在这一层写,当然有时候我们的代码可能就只是保存一下数据没啥业务逻辑,可能是直接调用一下 repo 的方式
1 | |
repo
这一层是数据持久层,像数据库存取,缓存的处理应该都在这一层做掉,还有可能后续我们变成调用一个微服务来实现,那么这个被调用的微服务也应该在这里做。
1 | |
wire_set.go
之前在 Go 工程化(三) 依赖注入框架 wire 这一节讲到过,我们使用 wire 作为我们的依赖注入框架,由于 wire 不能出现相同的 Provider 所以我们会在 internal 的每个子目录下创建一下 wire_set.go 用于构建 wire.Set 结构,到时我们在 cmd 下直接应用这个文件的内容就可以了
1 | |
cmd
cmd 下的二进制目录,我一般会包含四个文件
1 | |
server.go 在真实的项目当中我们 service 包下面一般会有多个 service 文件,对应不同的结构体,并且除了 internal 中的依赖外我们可能还会有很多公共的依赖,例如配置中心,日志,数据库等,我的习惯是构建一个新的结构,在这个结构当中我们把所有的注册还还有 wire.set 搞好,这样 main 函数就会很清爽,整体上也会比较整洁
1 | |
wire.go 经过 server.go 封装之后,wire.go 的代码就非常简单了
1 | |
main.go 我这里还没有像 kratos 把程序的启动和退出封装起来,如果封装了会更加优雅一点
1 | |
总结
我们回过头来看上面这两种结构,可以发现,第一种结构整体上职责相对没有那么清晰,就导致了在团队协作的过程中会出现很多二义性,导致最后越来越混乱,并且由于 model 层就是一个大锅饭,什么都往里面扔所以也就乱的不行了。
新的结构不仅仅进行了水平拆分还按照功能进行了垂直拆分,将定时任务和 http 服务的代码拆分开来,整体的结构都清晰了很多,并且由于我们大量使用依赖注入,所以代码的可测性非常的好,写单元测试非常容易。
但是这里也有一个坑,拆分的时候要注意,我第一次拆分想按照领域进行拆分,并且拆分的非常细,导致出现了很多服务,后面听过毛老师课上的讲解后重新 review 了一下发现其实这些服务边界没有那么清晰,即使我们以后拆微服务,也不会把这些拆成两个不同的微服务,所以后面再改了一次才构成了现在的结构。所以我们在进行垂直拆分的时候一定要多问问自己,或者多和团队的同学讨论一下。
最后想要业务开发的比较开心愉快,那基础设施的建设非常重要,像本文提到的很多代码只要我们统一了规范和结构都可以通过工具来自动生成。
我们下一篇文章见,加油打工人 💪(看完别忘了转发,订阅,点赞哦)
参考文献
- Go 进阶训练营-极客时间
- Go 工程化(一) 架构整洁之道阅读笔记 - Mohuishou
- Go 工程化(二) 项目目录结构 - Mohuishou
- Go 工程化(三) 依赖注入框架 wire - Mohuishou
- Go 工程化(四) API 设计上: 项目结构 & 设计 - Mohuishou
- Go 工程化(五) API 设计下: 基于 protobuf 自动生成 gin 代码 - Mohuishou
- Go 工程化(六) 配置管理 - Mohuishou
- Go 工程化(七) Go Module - Mohuishou
- Go 工程化(八) 单元测试 - Mohuishou
- https://github.com/favadi/protoc-go-inject-tag
- https://pkg.go.dev/github.com/jinzhu/copier
- https://github.com/go-kratos/kratos/blob/main/app.go
关注我获取更新



猜你喜欢
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处,禁止全文转载