Go可用性(五) 自适应限流
注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营, 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
序
在前面限流的三篇文章,我们学习了令牌桶、漏桶算法的原理、实现以及使用方式,不知道你有没有觉得这两种算法存在着一些问题。
这两种算法最大的一个问题就是他们都属于需要提前设置阈值的算法,基于 QPS 进行限流的时候最麻烦的就是这个阈值应该怎么设定。一般来说我们可以通过压测来决定这个阈值。
- 但是如果每个系统上线前都要经过很严格的压测,那么成本相对来说会比较大
- 并且我们很多时候压测都会在测试环境进行压测,测试环境一般来说和生产环境会有一定的差异,即使我们在生产环境做了压测,现在我们的应用都是以容器的形式跑在不同的宿主机上的,每台宿主机上的差异,以及不同的负载都会导致这个压测时的结果不一定就一定是正确的
- 当我们的机器型号、数量等发生改变时,之前压测的指标能不能用其实是一个问题,这些数据对于系统负载的影响其实不是线性的,举个例子之前一台机器,后面再加一台,负载就一定能到 2 倍么?其实是不一定的
- 如果需要修改限流的值,虽然之前我们将令牌桶的限流是可以动态调整,但是靠人去调整,如果真出现问题然后再叫运维或者是开发同学去调整可能黄花菜都凉了
既然这种方式有这么多的缺点,那有没有办法解决呢?答案就是今天讲到的 自适应限流
自适应限流
自适应限流怎么做
前面我们遇到的主要问题就是每个服务实例的限流阈值实际应该是动态变化的,我们应该根据系统能够承载的最大吞吐量,来进行限流,当当前的流量大于最大吞吐的时候就限制流量进入,反之则允许通过。那现在的问题就是
- 系统的吞吐量该如何计算?
- 什么时候系统的吞吐量就是最大的吞吐量了?
计算吞吐量:利特尔法则 L = λ * W
利特尔法则由麻省理工大学斯隆商学院(MIT Sloan School of Management)的教授 John Little﹐于 1961 年所提出与证明。它是一个有关提前期与在制品关系的简单数学公式,这一法则为精益生产的改善方向指明了道路。 —- MBA 智库百科 (mbalib.com)
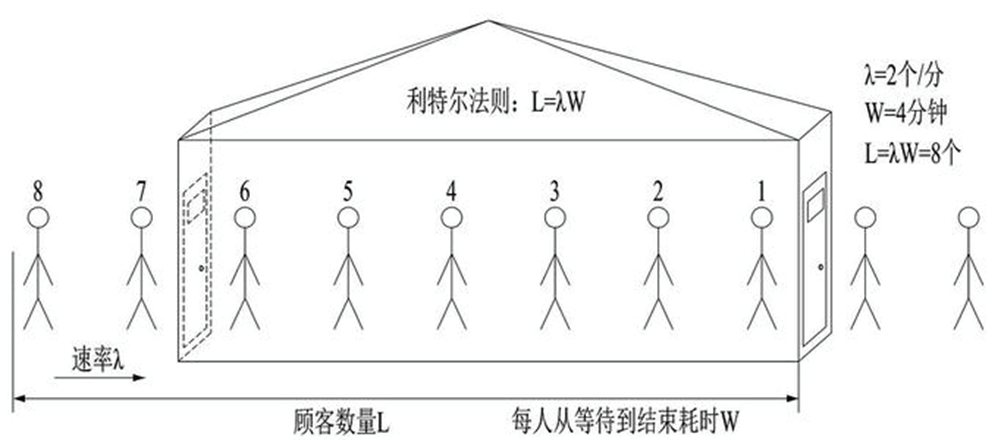
如上图所示,如果我们开一个小店,平均每分钟进店 2 个客人(λ),每位客人从等待到完成交易需要 4 分钟(W),那我们店里能承载的客人数量就是 2 * 4 = 8 个人
同理,我们可以将 λ 当做 QPS, W 呢是每个请求需要花费的时间,那我们的系统的吞吐就是 L = λ * W ,所以我们可以使用利特尔法则来计算系统的吞吐量。
什么时候系统的吞吐量就是最大的吞吐量?
首先我们可以通过统计过去一段时间的数据,获取到平均每秒的请求量,也就是 QPS,以及请求的耗时时间,为了避免出现前面 900ms 一个请求都没有最后 100ms 请求特别多的情况,我们可以使用滑动窗口算法来进行统计。
最容易想到的就是我们从系统启动开始,就把这些值给保存下来,然后计算一个吞吐的最大值,用这个来表示我们的最大吞吐量就可以了。但是这样存在一个问题是,我们很多系统其实都不是独占一台机器的,一个物理机上面往往有很多服务,并且一般还存在一些超卖,所以可能第一个小时最大处理能力是 100,但是这台节点上其他服务实例同时都在抢占资源的时候,这个处理能力最多就只能到 80 了
所以我们需要一个数据来做启发阈值,只要这个指标达到了阈值那我们就进入流控当中。常见的选择一般是 CPU、Memory、System Load,这里我们以 CPU 为例
只要我们的 CPU 负载超过 80% 的时候,获取过去 5s 的最大吞吐数据,然后再统计当前系统中的请求数量,只要当前系统中的请求数大于最大吞吐那么我们就丢弃这个请求。
kratos 自适应限流分析
限流公式
1 | |
cpu > 800表示 CPU 负载大于 80% 进入限流(Now - PrevDrop) < 1s这个表示只要触发过 1 次限流,那么 1s 内都会去做限流的判定,这是为了避免反复出现限流恢复导致请求时间和系统负载产生大量毛刺(MaxPass * MinRt * windows / 1000) < InFlight判断当前负载是否大于最大负载InFlight表示当前系统中有多少请求(MaxPass * MinRt * windows / 1000)表示过去一段时间的最大负载MaxPass表示最近 5s 内,单个采样窗口中最大的请求数MinRt表示最近 5s 内,单个采样窗口中最小的响应时间windows表示一秒内采样窗口的数量,默认配置中是 5s 50 个采样,那么 windows 的值为 10。
源码分析
BBR 结构体
1 | |
Allow: 判断请求是否允许通过
1 | |
这个方法主要是给中间件使用的
- 首先使用
shouldDrop方法判断这个请求是否应该丢弃 - 如果成功放行,那么当前系统中的请求数就 +1
- 然后返回一个
function用于请求结束之后- 统计请求的响应时间
- 如果请求成功了,给成功的请求数 +1
- 并且当前系统中的请求数量
Inflight-1
shouldDrop: 判断请求是否应该被丢弃
1 | |
这个方法其实就是开头讲到的限流公式了,逻辑如下图所示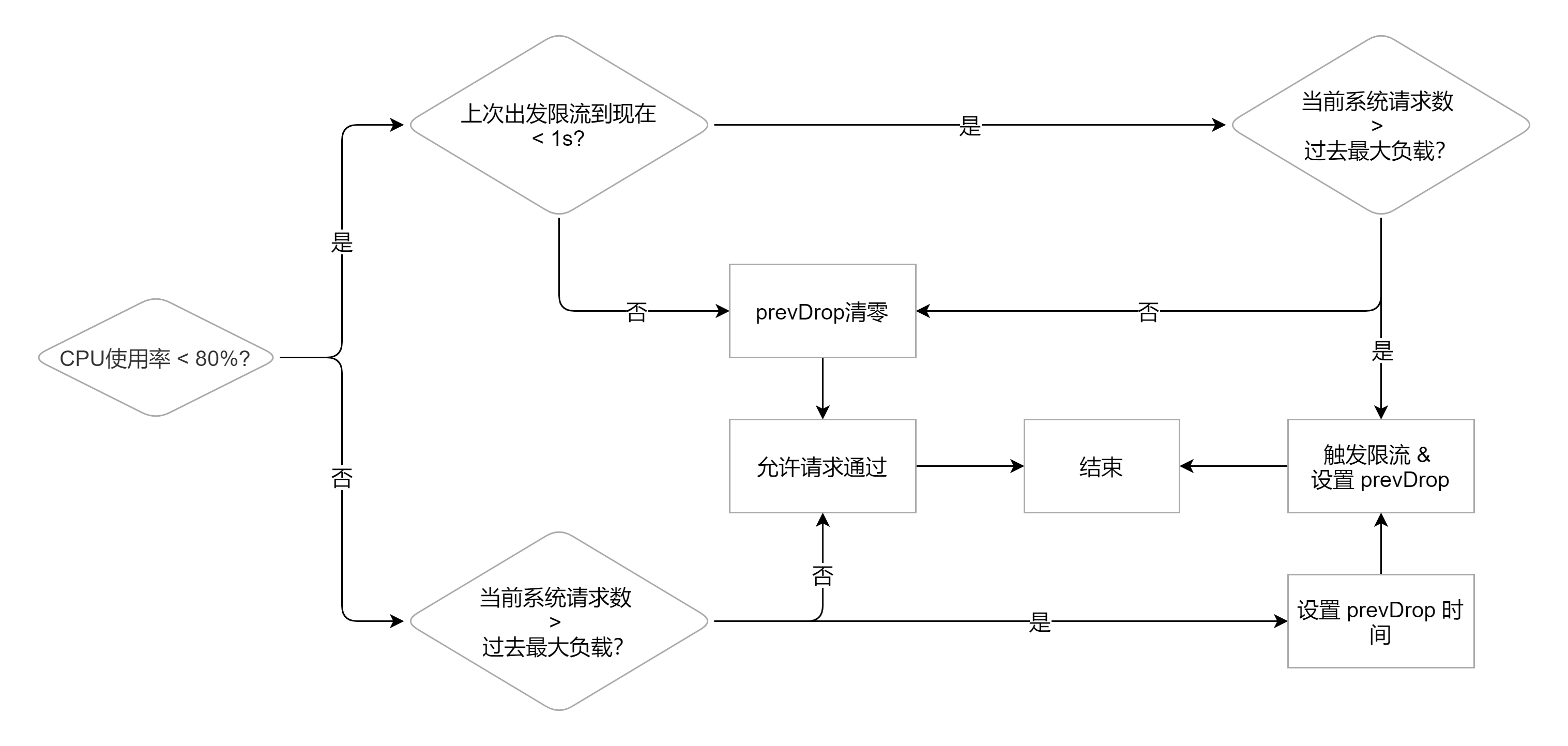
- 首先看 CPU 的使用率是否达到了阈值
- 如果没到,则回去判断一下上次触发限流到现在是否在一秒以内
- 如果在一秒内,就判断当前负载是否超过限制,如果超过了就需要丢弃
- 如果不在 1s 内或者是请求数量已经降下来了,那么就吧
prevDrop清零然后返回 false
- 如果到了,则判断一下当前负载是否超过限制
- 如果超过了,则设置丢弃时间
prevDrop,返回 true 需要丢弃请求 - 如果没超过直接返回 false
- 如果超过了,则设置丢弃时间
maxFlight: 系统的最大负载
1 | |
这个就是计算过去一段时间系统的最大负载是多少
总结
这篇文章我们讲了一下为什么需要自适应限流,令牌桶和漏桶这类需要手动设置 rps 算法的问题所在,了解了自适应限流的实现原理,最后看了一下 kratos 当中是如何实现自适应限流的。但是由于篇幅关系,CPU 的数据如何进行统计,文章中提到了很多次的滑动窗口是个什么原理这些知识点大家可以自行查看 kratos 中的源码,或者去看极客时间的 Go 进阶训练营都有讲到。
kratos 中的限流算法其实灵感源于 Google SRE,实现上参考了 sentinel,其中一个有意思的点是 sentinel 默认使用 load 作为启发阈值,而 kratos 使用了 cpu,kratos 为什么要使用 cpu 呢?这个大家可以自己想想(答案可以自行观看极客时间的 Go 进阶训练营)
而 sentinel 的实现其实是参考了 TCP 中的 BBR 算法,在 BBR 的基础上加上了 load 作为启发阈值的判断,所以多了解一下基础知识总是没错的,指不定当下遇到的场景就能解决。
参考文献
- Go 进阶训练营-极客时间
- B 站高可用架构实践 | 赵坤的个人网站 (kunzhao.org)
- 利特尔法则 - MBA 智库百科 (mbalib.com)
- 从流量控制算法谈网络优化 – 从 CUBIC 到 BBRv2 算法 | 亚马逊 AWS 官方博客 (amazon.com)
- kratos/ratelimit.md at v1.0.x · go-kratos/kratos (github.com)
- 限流器系列(3)–自适应限流 - 郝洪范的个人空间 - OSCHINA - 中文开源技术交流社区
- TCP congestion control - Wikipedia
- 系统自适应限流 · alibaba/Sentinel Wiki · GitHub
关注我获取更新



猜你喜欢
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处,禁止全文转载