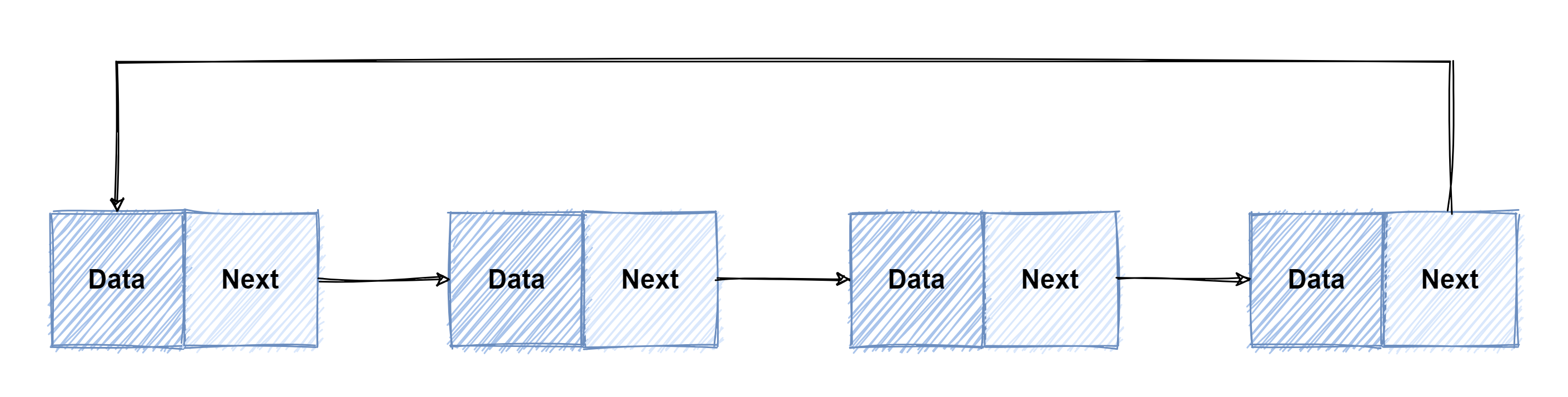
// Element 用于表示链表当中的节点 type Element struct { // next, prev 分别表示上个节点和下个节点 next, prev *Element
// 表示节点所在的元素 list *List
// 节点所保存的数据,也就是上面图中的 data Value interface{} }
// List 这是一个双向链表 // List 的零值是一个空链表 type List struct { // 根节点,List 其实是一个双向循环链表,root, root.prev 是尾节点, 尾节点的下一个节点指向 root // 根节点是一个哨兵节点,是为了用来简化节点操作使用的 root Element
// 链表的长度,不包括哨兵节点,也就是根节点 lenint }
看到这里我下意识的会有两个问题:
为什么在 Element 当中会持有一个 List 结构?
为什么需要一个单独的 List 结构体,直接要一个 Root 节点不就完事了么?
方法集
1 2 3 4 5 6 7 8 9 10 11
Remove(e *Element) interface{} // 删除一个节点 PushFront(v interface{}) *Element // 将值插入到链表头部 PushBack(v interface{}) *Element // 将值插入到链表尾部 InsertBefore(v interface{}, mark *Element) *Element // 在 mark 节点之前插入值 InsertAfter(v interface{}, mark *Element) *Element // 在 mark 节点之后插入值 MoveToFront(e *Element) // 将节点 e 移动至链表头部 MoveToBack(e *Element) // 将节点 e 移动至链表尾部 MoveBefore(e, mark *Element) // 将节点 e 移动到 mark 节点之前 MoveAfter(e, mark *Element) // 将节点 e 移动到 mark 节点之后 PushBackList(other *List) // 将链表 other 连接到当前链表之后 PushFrontList(other *List) // 将链表 other 连接到当前链表之前
// 将节点 e 插入 at 之后 func(l *List)insert(e, at *Element) *Element { // 假设 at.next 为 nt // 1. 将节点 e 的上一个节点指向 at e.prev = at // 2. 将节点 e 的下一个节点指向 nt e.next = at.next // 3. 这个时候 e.prev.next == at.next // 其实就是本来 at --> nt,修改为 at --> e e.prev.next = e // 4. e.next.prev == nt.prev // 本来 at <--- nt,修改为 e <--- nt e.next.prev = e e.list = l l.len++ return e }
remove
1 2 3 4 5 6 7 8 9 10 11
// remove removes e from its list, decrements l.len, and returns e. func(l *List)remove(e *Element) *Element { e.prev.next = e.next e.next.prev = e.prev // 这里为了避免内存泄漏的操作可以学习 e.next = nil// avoid memory leaks e.prev = nil// avoid memory leaks e.list = nil l.len-- return e }
move
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// move moves e to next to at and returns e. func(l *List)move(e, at *Element) *Element { if e == at { return e } // 先把当前节点从原来的位置移除 e.prev.next = e.next e.next.prev = e.prev
// 再将当前节点 e 插入到 at 节点之后 e.prev = at e.next = at.next e.prev.next = e e.next.prev = e
func(l *List)MoveToFront(e *Element) { if e.list != l || l.root.next == e { return } // see comment in List.Remove about initialization of l l.move(e, &l.root) }
2. 为什么需要一个单独的 List 结构体,直接要一个 Root 节点不就完事了么?
看之前的 List 的结构我们可以发现,在结构体中包含了一个 len ,这样可以避免需要取长度的时候每次都需要从头到尾遍历一遍
如何实现一个并发安全的 Container/list?
接下来,我们使用 go test -race . 测试是否存在并发安全的问题
标准库包
1 2 3 4 5 6 7 8 9 10 11 12 13
funcTestList(t *testing.T) { l := list.New() wg := sync.WaitGroup{} wg.Add(1) gofunc() { for i := 0; i < 10; i++ { l.PushBack(i) } wg.Done() }() l.PushBack(11) wg.Wait() }
测试结果如下,可以明显的看到存在并发问题
1 2 3 4 5 6 7
go test -v -timeout 1s -race -run ^TestList$ ./... === RUN TestList ================== WARNING: DATA RACE Read at 0x00c00006e330 by goroutine 8: container/list.(*List).lazyInit() /usr/local/go/src/container/list/list.go:86 +0xb2
稍作改造
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// List 链表 type List struct { *list.List mu sync.Mutex }
// New 新建链表 funcNew() *List { return &List{List: list.New()} }
go test -v -timeout 1s -race -run ^TestList_PushBack$ ./... === RUN TestList_PushBack --- PASS: TestList_PushBack (0.00s) PASS ok github.com/mohuishou/go-algorithm/01_list/list (cached)