注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营, 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
楔子
使用通信共享内存
“不要通过共享内存来通信,我们应该使用通信来共享内存” 这句话想必大家已经非常熟悉了,在官方的博客,初学时的教程,甚至是在 Go 的源码中都能看到,我们之前讲 sync 包的时候也有提到过。
无论是通过共享内存来通信还是通过通信来共享内存,最终我们应用程序都是读取的内存当中的数据,只是前者是直接读取内存的数据,而后者是通过发送消息的方式来进行同步。而通过发送消息来同步的这种方式常见的就是 Go 采用的 CSP(Communication Sequential Process) 模型以及 Erlang 采用的 Actor 模型,这两种方式都是通过通信来共享内存。

大部分的语言采用的都是第一种方式直接去操作内存,然后通过互斥锁,CAS 等操作来保证并发安全。Go 引入了 Channel 和 Goroutine 实现 CSP 模型来解耦这个操作,这样做的好处是在 Goroutine 当中我们就不用手动去做资源的锁定与释放,同时将生产者和消费者进行了解耦,Channel 其实和消息队列很相似。而 Actor 模型和 CSP 模型都是通过发送消息来共享内存,但是它们之间最大的区别就是 Actor 模型当中并没有一个独立的 Channel 组件,而是 Actor 与 Actor 之间直接进行消息的发送与接收,每个 Actor 都有一个本地的“信箱”消息都会先发送到这个“信箱当中”。
小结
- 相对于互斥锁,原子操作而言 channel 是一个更高层级的抽象,使用 channel 会更加方便,心智成本也更低,同时也更不容易出错(channel 保证了并发安全),后面就会讲到,由于 Channel 底层也是通过这些低级的同步原语实现的,所以性能上会差一些,如果有极高的性能要求时也可以用 sync 包中提供的低级同步原语
- 使用 channel 可以帮助我们解耦生产者和消费者,可以降低并发当中的耦合
happens before
在 Week03: Go 并发编程(二) Go 内存模型 这篇文章当中讲到同步的时候,Channel 相关部分我们特意略过了,在后面 channel 部分我们就会详细的讲到 channel 的使用以及是怎么实现的,这里先回顾一下 happens before 相关的知识点,详细可以看之前的那篇文章。
**happens before 定义: **如果 e1 发生在 e2 之前,那么我们就说 e2 发生在 e1 之后,如果 e1 既不在 e2 前,也不在 e2 之后,那我们就说这俩是并发的
但是在我们进行并发编程的过程中由于编译器和 CPU 的各种优化,所以在并发执行的时候并不一定按照代码书写的顺序进行执行(在单个 Goroutine 是可以保证的),所以我们就要采用各种同步原语来保证有序,在 Go 中最常用的就是 Channel,接下来我们就进入正题吧。
channel:
- channel 上的发送操作总在对应的接收操作完成前发生
- 如果 channel 关闭后从中接收数据,接受者就会收到该 channel 返回的零值
- 从无缓冲的 channel 中进行的接收,要发生在对该 channel 进行的发送完成前
这些看起来会比较绕,记住这几条规则,我们接着往下走,希望可以解决你的困惑
channel
基本用法
channel 的关键字为 chan ,使用时还需要给 channel 指定一个类型,所以完整的就是 chan T ,使用 <- 表示 channel 的数据流向,在定义变量时,我们也可以使用 <- chan T 、 chan<- T 来分别表示只读和只写的 channel。
channel 的初始化采用 make(chan T, cap) 表示, cap 为可选参数,如果不填默认值为 0 表示创建了一个无缓冲的 channel。接下来我们看一个简单的例子,来了解 channel 的基本使用方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| package main
import (
"fmt"
)
func read(c <-chan int) {
fmt.Println("read:", <-c)
}
func write(c chan<- int) {
c <- 0
}
func main() {
c := make(chan int)
go read(c)
write(c)
}
|
最后会输出 read: 0 , 注意我们这里使用的是无缓冲的 channel,如果换成有缓存的,这里有可能就不会输出了,因为
- channel 上的发送操作总在对应的接收操作完成前发生,所以在 read 还没有完成时候,write 就已经开始写入了
- 从无缓冲的 channel 中进行的接收,要发生在对该 channel 进行的发送完成前,如果是无缓冲的 channel, write 还没写入结束,read 就已经开始接收了,所以可以保证 read 执行,但是反过来如果有缓冲,那么 read 可能还没开始 write 就结束了,所以就有可能什么都不输出就结束了
关于有无缓冲的 channel 有两张图非常经典,基本上看完就明白了,建议阅读一下原文,在参考文献 [14] 中
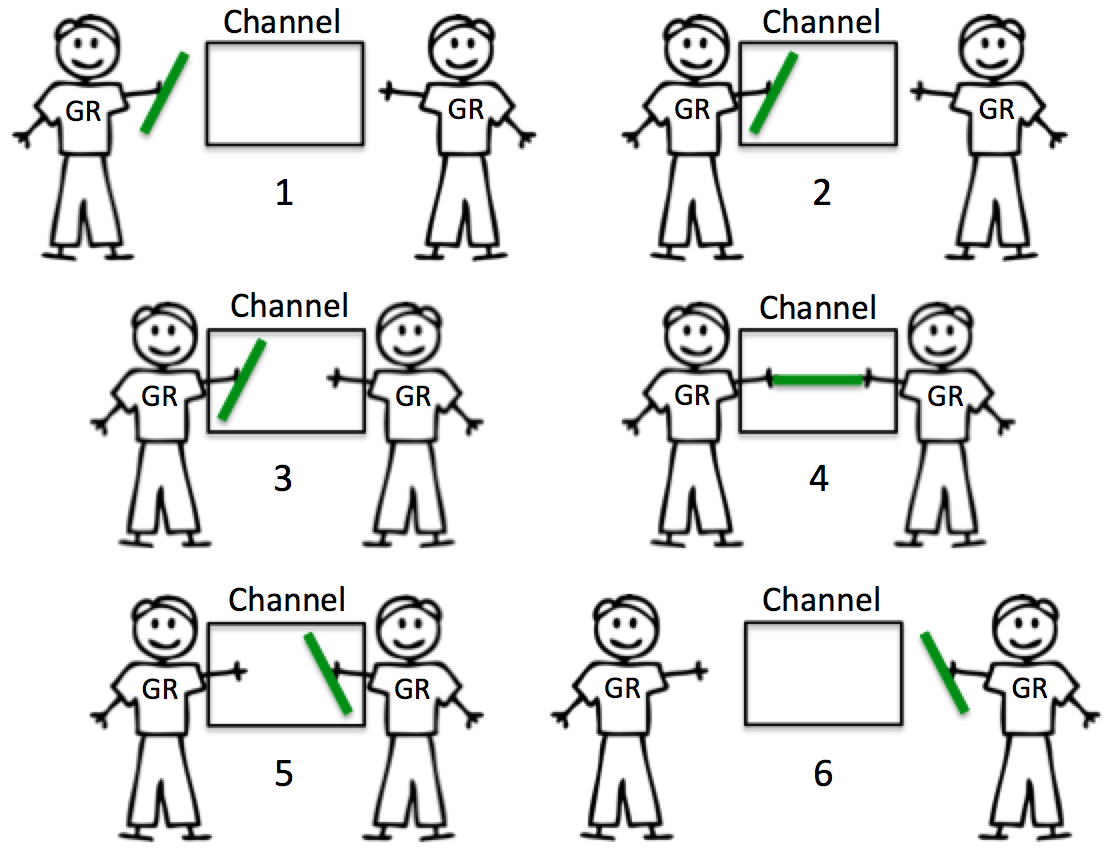
无缓冲 channel
如下图所示,无缓冲的 channel 会阻塞直到数据接收完成,常用于两个 goroutine 互相等待同步
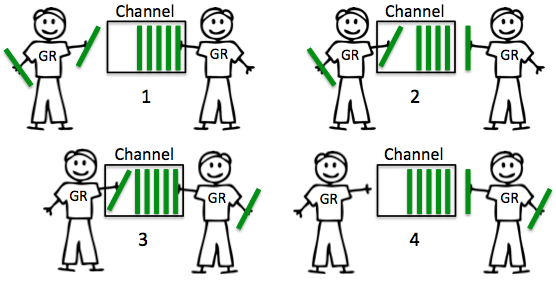
有缓冲 channel
有缓冲的 channel 如果在缓冲区未满的情况下发送是不阻塞的,在缓冲区不为空时,接收是不阻塞的
源码分析
大概了解了 channel 的使用方法和原理之后我们接下来就进入稍微硬核一些的源码模式
数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
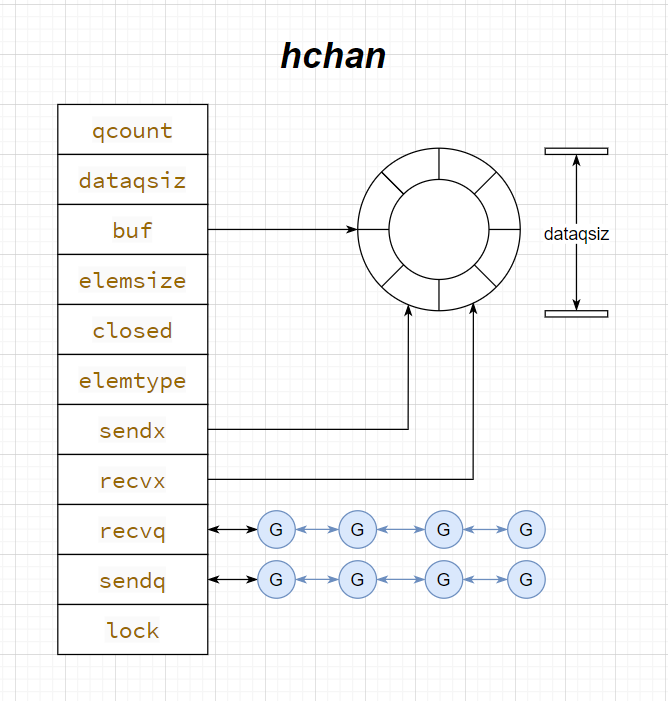
| type hchan struct {
qcount uint
dataqsiz uint
buf unsafe.Pointer
elemsize uint16
closed uint32
elemtype *_type
sendx uint
recvx uint
recvq waitq
sendq waitq
lock mutex
}
type waitq struct {
first *sudog
last *sudog
}
|
如下图所示,channel 底层其实是一个循环队列
创建
在 Go 中我们使用 make(chan T, cap) 来创建 channel,make 语法会在编译时,转换为 makechan64 和 makechan
1
2
3
4
5
6
7
| func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}
|
makechan64 主要是做了一下检查,最终还是会调用 makechan ,在看 makechan 源码之前,我们先来看两个全局常量,接下来会用到
1
2
3
4
| const (
maxAlign = 8
hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1))
)
|
maxAlign 是内存对齐的最大值,这个等于 64 位 CPU 下的 cacheline 的大小hchanSize 计算 unsafe.Sizeof(hchan{}) 最近的 8 的倍数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| func makechan(t *chantype, size int) *hchan {
elem := t.elem
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.ptrdata == 0:
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
return c
}
|
注释已经写得很全了,简单做个小结:
- 创建时会做一些检查
- 元素大小不能超过 64K
- 元素的对齐大小不能超过 maxAlign 也就是 8 字节
- 计算出来的内存是否超过限制
- 创建时的策略
- 如果是无缓冲的 channel,会直接给 hchan 分配内存
- 如果是有缓冲的 channel,并且元素不包含指针,那么会为 hchan 和底层数组分配一段连续的地址
- 如果是有缓冲的 channel,并且元素包含指针,那么会为 hchan 和底层数组分别分配地址
发送数据
我们在 x <- chan T 进行发送数据的时候最终会被编译成 chansend1
1
2
3
| func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
|
而 chansend1 最终还是调用了 chansend 主要的逻辑都在 chansend 上面,注意看下方源码和注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if !block && c.closed == 0 && full(c) {
return false
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
if !block {
unlock(&c.lock)
return false
}
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
KeepAlive(ep)
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if gp.param == nil {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
return true
}
|
send
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
|
小结
向 channel 中发送数据时大概分为两大块,检查和数据发送,而数据发送又分为三种情况
- 如果 channel 的
recvq 存在阻塞等待的接收数据的 goroutine 那么将会直接将数据发送给第一个等待的 goroutine- 这里会直接将数据拷贝到
x <-ch 接收者的变量 x 上 - 然后将接收者的 Goroutine 修改为可运行状态,并把它放到发送方所在处理器的 runnext 上等待下一次调度时执行。
- 如果 channel 是有缓冲的,并且缓冲区没有满,这个时候就会把数据放到缓冲区中
- 如果 channel 的缓冲区满了,这个时候就会走阻塞发送的流程,获取到 sudog 之后将当前 Goroutine 挂起等待唤醒,唤醒后将相关的数据解绑,回收掉 sudog
接收数据
在 Go 中接收 channel 数据有两种方式
x <- ch 编译时会被转换为 chanrecv1x, ok <- ch 编译时会被转换为 chanrecv2
chanrecv1 和 chanrecv2 没有多大区别,只是 chanrecv2 比 chanrecv1 多了一个返回值,最终都是调用的 chanrecv 来实现的接收数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if !block && empty(c) {
if atomic.Load(&c.closed) == 0 {
return
}
if empty(c) {
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
lock(&c.lock)
if c.closed != 0 && c.qcount == 0 {
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
closed := gp.param == nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, !closed
}
|
recv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if ep != nil {
recvDirect(c.elemtype, sg, ep)
}
} else {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
|
**小结: **数据接收和发送其实大同小异,也是分为检查和数据接收,数据接收又分三种情况
- 直接获取数据,如果当前有阻塞的发送者 Goroutine 走这条路
- 如果是无缓冲 channel,直接从发送者那里把数据拷贝给接收变量
- 如果是有缓冲 channel,并且 channel 已经满了,就先从 channel 的底层数组拷贝数据,再把阻塞的发送者 Goroutine 的数据拷贝到 channel 的循环队列中
- 从 channel 的缓冲中获取数据,有缓冲 channel 并且缓存队列有数据时走这条路
- 阻塞接收,剩余情况走这里
- 和发送类似,先获取当前 Goroutine 信息,构造 sudog 加入到 channel 的 recvq 上
- 然后休眠当前 Goroutine 等待唤醒
- 唤醒后做一些清理工作,释放 sudog 返回
关闭 channel
我们使用 close(ch) 来关闭 channel 最后会调用 runtime 中的 closechan 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
c.closed = 1
var glist gList
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = nil
glist.push(gp)
}
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = nil
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
|
小结:
- 关闭一个 nil 的 channel 和已关闭了的 channel 都会导致 panic
- 关闭 channel 后会释放所有因为 channel 而阻塞的 Goroutine
使用场景
关于 channel 的使用场景在 Go 语言 101 当中已经很完善了,如果感兴趣可以看一下参考文献[5],我这里只讲一些常见或是我觉得有趣的例子
1. 通过关闭 channel 实现一对多的通知
刚刚讲到了关闭 channel 时会释放所有阻塞的 Goroutine,所以我们就可以利用这个特性来做一对多的通知,除了一对多之外我们还用了 done 做了多对一的通知,当然多对一这种情况还是建议直接使用 WaitGroup 即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| package main
import (
"fmt"
"time"
)
func run(stop <-chan struct{}, done chan<- struct{}) {
for {
select {
case <-stop:
fmt.Println("stop...")
done <- struct{}{}
return
case <-time.After(time.Second):
fmt.Println("hello")
}
}
}
func main() {
stop := make(chan struct{})
done := make(chan struct{}, 10)
for i := 0; i < 10; i++ {
go run(stop, done)
}
time.Sleep(5 * time.Second)
close(stop)
for i := 0; i < 10; i++ {
<-done
}
}
|
2. 使用 channel 做异步编程(future/promise)
其实最开始的例子就是这种情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| package main
import (
"fmt"
)
func read(c <-chan int) {
fmt.Println("read:", <-c)
}
func write(c chan<- int) {
c <- 0
}
func main() {
c := make(chan int)
go read(c)
write(c)
}
|
3. 超时控制
具体可以看案例一里面的 run 方法, 不过超时控制还是建议使用 context
1
2
3
4
5
6
7
8
9
10
11
12
13
| func run(stop <-chan struct{}, done chan<- struct{}) {
for {
select {
case <-stop:
fmt.Println("stop...")
done <- struct{}{}
return
case <-time.After(time.Second):
fmt.Println("hello")
}
}
}
|
总结
这篇文章从资料收集,到源码阅读再到最终成文花了快半个月的时间了,不过写完之后就我个人而言是收获满满的,不知到能不能为屏幕前的你带来一点点启发,如果可以那就太赞了。这篇文章从最开始的理论 csp/actor 到 hanpens before 再到 channel 的基本用法,源码实现,最后讲到了一些使用场景,但是由于长度精力还是个人水平等多种限制有的地方讲解还是不够细致,具体强烈建议阅读一些参考文献里面的十几篇文章,每一个都值得细细品味。
我们下一篇文章见 👀
参考文献
- The Go Programming Language Specification - The Go Programming Language
- Go advanced concurrency patterns: part 3 (channels) - Blog Title
- Go 语言 Channel 实现原理精要 | Go 语言设计与实现
- Go Channel 详解 | 鸟窝
- 通道 - Go 语言 101(通俗版 Go 白皮书)
- 通道用例大全 - Go 语言 101(通俗版 Go 白皮书)
- 如何优雅地关闭通道 - Go 语言 101(通俗版 Go 白皮书)
- 深度解密 Go 语言之 channel | qcrao
- 为什么使用通信来共享内存 - 面向信仰编程
- http://www.usingcsp.com/cspbook.pdf
- 一文带你解密 Go 语言之通道 channel
- Golang 源码分析系列之 Channel 底层实现 | Tink’s Blog
- The Behavior Of Channels
- The Nature Of Channels In Go
关注我获取更新
猜你喜欢


