Go可用性(六) 熔断
注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
注:本文所有示例代码都可以在 blog-code 仓库中找到
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营, 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
在前面的几篇文章当中,无论是令牌桶、漏桶还是自适应限流的方法,总的来说都是服务端的单机限流方式。虽然服务端限流虽然可以帮助我们抗住一定的压力,但是拒绝请求毕竟还是有成本的。如果我们的本来流量可以支撑 1w rps,加了限流可以支撑在 10w rps 的情况下仍然可以提供 1w rps 的有效请求,但是流量突然再翻了 10 倍,来到 100w rps 那么服务该挂还是得挂。
所以我们的可用性建设不仅仅是服务端做建设就可以万事大吉了,得在整个链路上的每个组件都做好自己的事情才行,今天我们就来一起看一下客户端上的限流措施:熔断。
熔断器
![熔断器<sup id="fnref:2" class="footnote-ref"><a href="#fn:2" rel="footnote"><span class="hint--top hint--rounded" aria-label="熔断原理与实现Golang版 https://www.jianshu.com/p/0ee350cde543
">[2]</span></a></sup>](https://img.lailin.xyz/image/20210504154754.png)
如上图[2]所示,熔断器存在三个状态:
- 关闭(closed): 关闭状态下没有触发断路保护,所有的请求都正常通行
- 打开(open): 当错误阈值触发之后,就进入开启状态,这个时候所有的流量都会被节流,不运行通行
- 半打开(half-open): 处于打开状态一段时间之后,会尝试尝试放行一个流量来探测当前 server 端是否可以接收新流量,如果这个没有问题就会进入关闭状态,如果有问题又会回到打开状态
hystrix-go
熔断器中比较典型的实现就是 hystrix,Golang 也有对应的版本,我们先来看一下 hystrix-go 是怎么实现的
案例
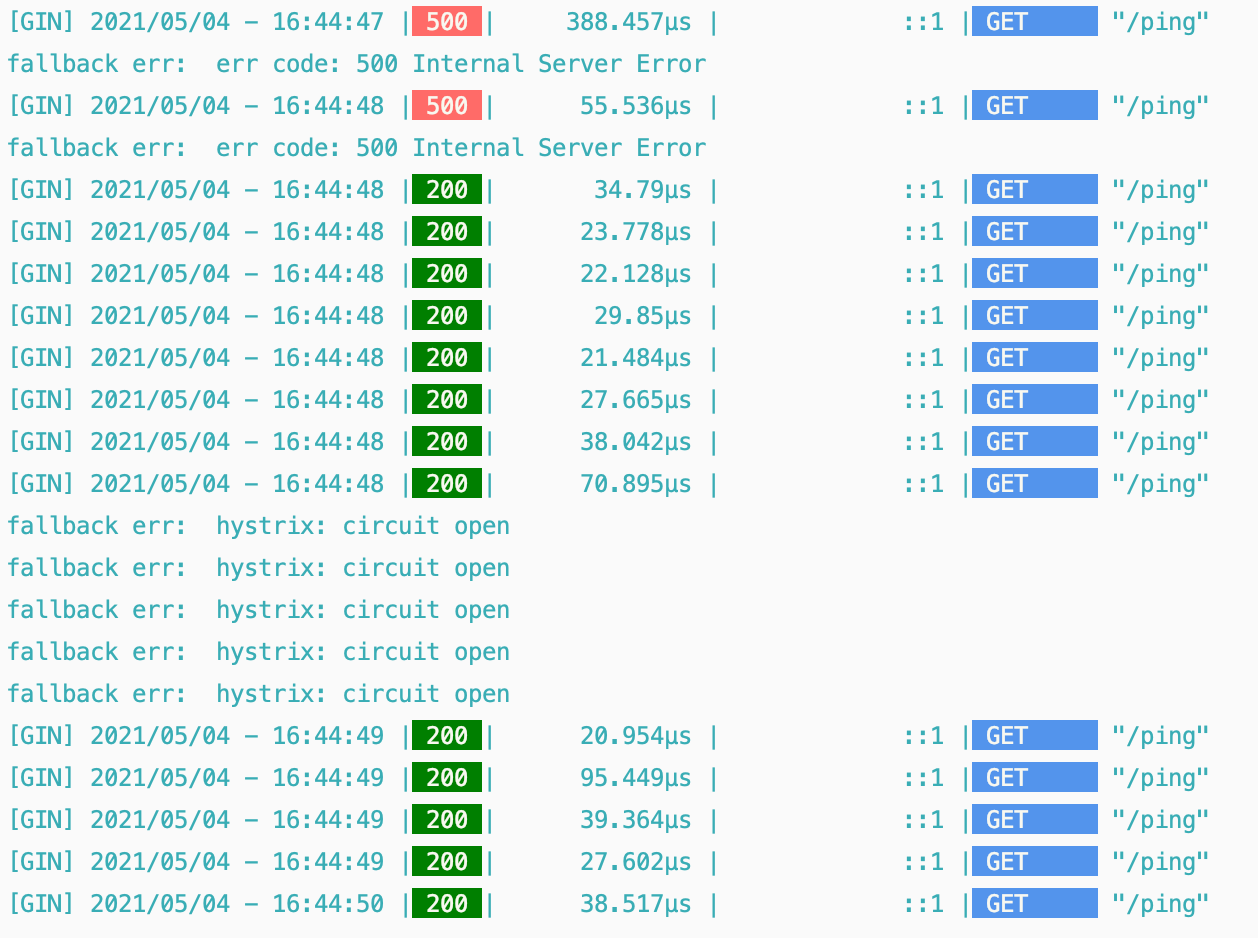
先看一个使用案例,首先我们使用 gin 启动一个服务端,这个服务端主要是前 200ms 的请求都会返回 500,之后的请求都会返回 200
1 | |
然后配置 hystrix,hystrix.ConfigureCommand(command name, config) hystrix 的配置是按照每个 command 进行配置,使用的时候我们也需要传递一个 command,下面的配置就是我们的请求数量大于等于 10 个并且错误率大于等于 20% 的时候就会触发熔断器开关,熔断器打开 500ms 之后会进入半打开的状态,尝试放一部分请求去访问
1 | |
然后我们使用一个循环当做客户端代码,会请求 20 次,每一个请求消耗 100ms
1 | |
所以我们执行的结果就是,前面 2 个请求报 500,等到发起了 10 个请求之后就会进入熔断, 500ms 也就是发出 5 个请求之后就会重新去请求服务端
hystrix-go 核心实现
核心实现的方法是 AllowRequest,IsOpen判断当前是否处于熔断状态,allowSingleTest就是去看是否过了一段时间需要重新进行尝试
1 | |
IsOpen先看当前是否已经打开了,如果已经打开了就直接返回就行了,如果还没打开就去判断
- 请求数量是否满足要求
- 请求的错误率是否过高,如果两个都满足就会打开熔断器
1 | |
hystrix-go已经可以比较好的满足我们的需求,但是存在一个问题就是一旦触发了熔断,在一段时间之类就会被一刀切的拦截请求,所以我们来看看 google sre 的一个实现
Google SRE 过载保护算法
$$
max(0, \frac{requests - K * accepts}{requests + 1})
$$
算法如上所示,这个公式计算的是请求被丢弃的概率[3]
- requests: 一段时间的请求数量
- accepts: 成功的请求数量
- K: 倍率,K 越小表示越激进,越小表示越容易被丢弃请求
这个算法的好处是不会直接一刀切的丢弃所有请求,而是计算出一个概率来进行判断,当成功的请求数量越少,K越小的时候 $requests - K * accepts$ 的值就越大,计算出的概率也就越大,表示这个请求被丢弃的概率越大
Kratos 实现分析
1 | |
总结
可用性仅靠服务端来保证是不靠谱的,只有整条链路上的所有服务都做好了自己可用性相关的建设我们的服务 SLA 最后才能够有保证。今天我们讲了 hystrix-go 和 kratos 两种熔断的实现方式,kratos采用 Google SRE 的实现的好处就是没有半开的状态,也没有完全开启的状态,而是通过一个概率来进行判断我们的流量是否应该通过,这样没有那么死板,也可以保证我们错误率比较高的时候不会大量请求服务端,给服务端喘息恢复的时间。
参考文献
- 极客时间: Go 进阶训练营 https://u.geekbang.org/subject/go?utm_source=lailin.xyz&utm_medium=lailin.xyz ↩
- 熔断原理与实现Golang版 https://www.jianshu.com/p/0ee350cde543 ↩
- Google SRE https://sre.google/sre-book/handling-overload/#eq2101 ↩
- hystrix-go https://github.com/afex/hystrix-go/ ↩
- kratos 实现 https://github.com/go-kratos/kratos/blob/v1.0.x/pkg/net/netutil/breaker/sre_breaker.go ↩
关注我获取更新



猜你喜欢
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处,禁止全文转载