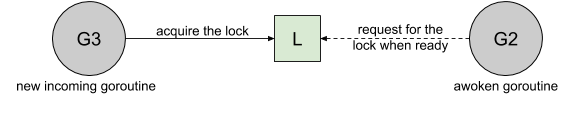Mutex 结构体由 statesema 两个 4 字节成员组成,其中 state 表示了当前锁的状态, sema 是用于控制锁的信号量 state 字段的最低三位表示三种状态,分别是 mutexLockedmutexWokenmutexStarving ,剩下的用于统计当前在等待锁的 goroutine 数量
mutexLocked 表示是否处于锁定状态
mutexWoken 表示是否处于唤醒状态
mutexStarving 表示是否处于饥饿状态
加锁
回味一下上面看到的流程图,我们来看看互斥锁是如何加锁的
1 2 3 4 5 6 7 8
func(m *Mutex)Lock() { // Fast path: grab unlocked mutex. if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) { return } // Slow path (outlined so that the fast path can be inlined) m.lockSlow() }
当我们调用 Lock 方法的时候,会先尝试走 Fast Path,也就是如果当前互斥锁如果处于未加锁的状态,尝试加锁,只要加锁成功就直接返回
func(m *Mutex)lockSlow() { var waitStartTime int64// 等待时间 starving := false// 是否处于饥饿状态 awoke := false// 是否处于唤醒状态 iter := 0// 自旋迭代次数 old := m.state for { // Don't spin in starvation mode, ownership is handed off to waiters // so we won't be able to acquire the mutex anyway. if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) { // Active spinning makes sense. // Try to set mutexWoken flag to inform Unlock // to not wake other blocked goroutines. if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 && atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) { awoke = true } runtime_doSpin() iter++ old = m.state continue }
在 lockSlow 方法中我们可以看到,有一个大的 for 循环,不断的尝试去获取互斥锁,在循环的内部,第一步就是判断能否自旋状态。 进入自旋状态的判断比较苛刻,具体需要满足什么条件呢? runtime_canSpin 源码见下方
当前互斥锁的状态是非饥饿状态,并且已经被锁定了
自旋次数不超过 4 次
cpu 个数大于一,必须要是多核 cpu
当前正在执行当中,并且队列空闲的 p 的个数大于等于一
1 2 3 4 5 6 7 8 9 10 11 12
// Active spinning for sync.Mutex. //go:linkname sync_runtime_canSpin sync.runtime_canSpin //go:nosplit funcsync_runtime_canSpin(i int)bool { if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 { returnfalse } if p := getg().m.p.ptr(); !runqempty(p) { returnfalse } returntrue }
new := old // Don't try to acquire starving mutex, new arriving goroutines must queue. if old&mutexStarving == 0 { new |= mutexLocked } if old&(mutexLocked|mutexStarving) != 0 { new += 1 << mutexWaiterShift } // The current goroutine switches mutex to starvation mode. // But if the mutex is currently unlocked, don't do the switch. // Unlock expects that starving mutex has waiters, which will not // be true in this case. if starving && old&mutexLocked != 0 { new |= mutexStarving } if awoke { // The goroutine has been woken from sleep, // so we need to reset the flag in either case. ifnew&mutexWoken == 0 { throw("sync: inconsistent mutex state") } new &^= mutexWoken }
if atomic.CompareAndSwapInt32(&m.state, old, new) { if old&(mutexLocked|mutexStarving) == 0 { break// locked the mutex with CAS } // If we were already waiting before, queue at the front of the queue. queueLifo := waitStartTime != 0 if waitStartTime == 0 { waitStartTime = runtime_nanotime() } runtime_SemacquireMutex(&m.sema, queueLifo, 1) starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs old = m.state if old&mutexStarving != 0 { // If this goroutine was woken and mutex is in starvation mode, // ownership was handed off to us but mutex is in somewhat // inconsistent state: mutexLocked is not set and we are still // accounted as waiter. Fix that. if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 { throw("sync: inconsistent mutex state") } delta := int32(mutexLocked - 1<<mutexWaiterShift) if !starving || old>>mutexWaiterShift == 1 { // Exit starvation mode. // Critical to do it here and consider wait time. // Starvation mode is so inefficient, that two goroutines // can go lock-step infinitely once they switch mutex // to starvation mode. delta -= mutexStarving } atomic.AddInt32(&m.state, delta) break } awoke = true iter = 0 }
// 解锁一个没有锁定的互斥量会报运行时错误 // 解锁没有绑定关系,可以一个 goroutine 锁定,另外一个 goroutine 解锁 func(m *Mutex)Unlock() { // Fast path: 直接尝试设置 state 的值,进行解锁 new := atomic.AddInt32(&m.state, -mutexLocked) // 如果减去了 mutexLocked 的值之后不为零就会进入慢速通道,这说明有可能失败了,或者是还有其他的 goroutine 等着 ifnew != 0 { // Outlined slow path to allow inlining the fast path. // To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock. m.unlockSlow(new) } }
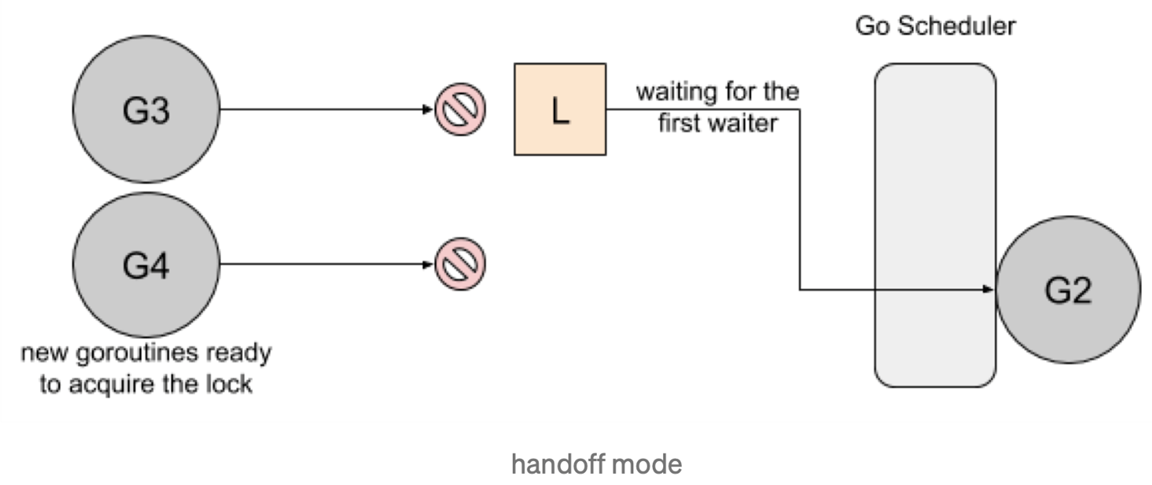
func(m *Mutex)unlockSlow(newint32) { // 解锁一个没有锁定的互斥量会报运行时错误 if (new+mutexLocked)&mutexLocked == 0 { throw("sync: unlock of unlocked mutex") } // 判断是否处于饥饿模式 ifnew&mutexStarving == 0 { // 正常模式 old := new for { // 如果当前没有等待者.或者 goroutine 已经被唤醒或者是处于锁定状态了,就直接返回 if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 { return } // 唤醒等待者并且移交锁的控制权 new = (old - 1<<mutexWaiterShift) | mutexWoken if atomic.CompareAndSwapInt32(&m.state, old, new) { runtime_Semrelease(&m.sema, false, 1) return } old = m.state } } else { // 饥饿模式,走 handoff 流程,直接将锁交给下一个等待的 goroutine,注意这个时候不会从饥饿模式中退出 runtime_Semrelease(&m.sema, true, 1) } }
❯ go test -race -bench=. goos: linux goarch: amd64 pkg: github.com/mohuishou/go-training/Week03/blog/04_sync/02_rwmutex BenchmarkMutexConfig-41795776912 ns/op BenchmarkRWMutexConfig-43416203425 ns/op PASS ok github.com/mohuishou/go-training/Week03/blog/04_sync/02_rwmutex 3.565s
func(rw *RWMutex)RLock() { if atomic.AddInt32(&rw.readerCount, 1) < 0 { // A writer is pending, wait for it. runtime_SemacquireMutex(&rw.readerSem, false, 0) } }
func(rw *RWMutex)RUnlock() { if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 { // Outlined slow-path to allow the fast-path to be inlined rw.rUnlockSlow(r) } }
func(rw *RWMutex)Lock() { // First, resolve competition with other writers. rw.w.Lock() // Announce to readers there is a pending writer. r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders // Wait for active readers. if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 { runtime_SemacquireMutex(&rw.writerSem, false, 0) } }
func(rw *RWMutex)Unlock() { // Announce to readers there is no active writer. r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders) if r >= rwmutexMaxReaders { race.Enable() throw("sync: Unlock of unlocked RWMutex") } // Unblock blocked readers, if any. for i := 0; i < int(r); i++ { runtime_Semrelease(&rw.readerSem, false, 0) } }