k8s job 为何迟迟不能结束?
注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
注:本文所有示例代码都可以在 blog-code 仓库中找到
前情提要
最近我们踩了一个之前很难遇到的坑,k8s 集群内同时并发运行的 job 2000+,一个 job 只有一个 Pod,一次运行一般 1 - 2min 就可以结束,但是线上数据统计发现每分钟新增的数据只有几十条,这个很不符合常理,关键是还没有报错。
因为我们的 job 很多,加上已完成未删除的 job 有上万个同时存在,并且 controller 会根据 cr 的需求不断地增删对应的 job,所以排查起来相对比较困难。
最后发现有一个 job 执行了 3h 都还没有执行完毕,这个成功的引起了我的注意,查看发现这个 job 的确没有完成,并且这个 job 关联的 pod 才刚刚创建,job 的信息里面也只有一个 active: 1 并没有失败的 job 出现
然后去腾讯云查看 k8s 的审计日志,离谱的事情来了
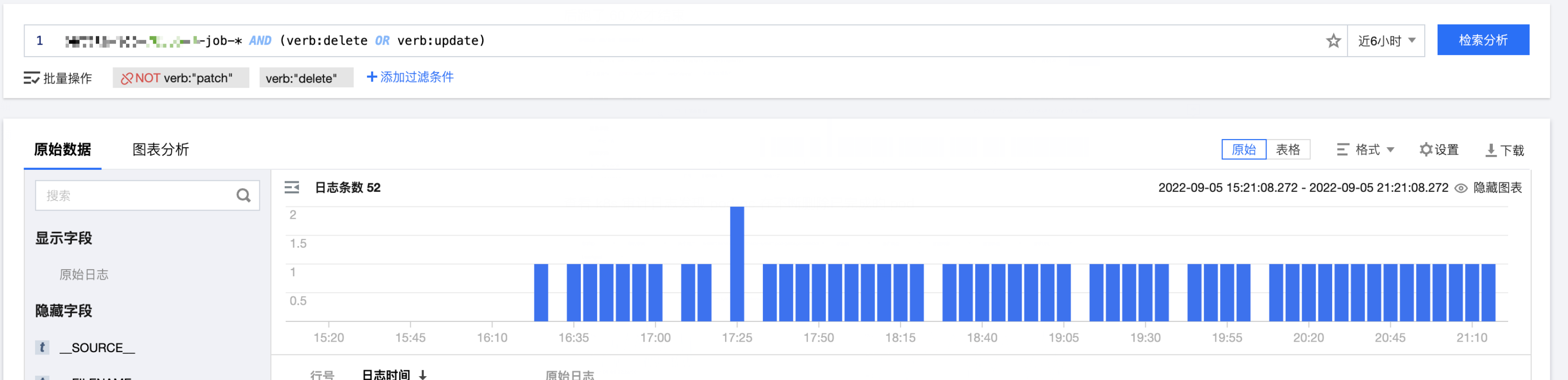
这个 job 对应的 pod 被 pod gc 删除了 50 次,然后查看上线服务的日志也发现存在大量的重复数据上报请求被丢弃掉了。
为什么 Pod 刚成功就被删除?
省流版: 来自官网的温馨提示
Job 控制器(Controller) 依靠计算集群中存在的 Pod 来跟踪作业状态。 也就是说,维持一个统计
succeeded和failed的 Pod 的计数器。 然而,Pod 可以因为一些原因被移除,包括:
- 当一个节点宕机时,垃圾收集器会删除孤立(Orphan)Pod。
- 垃圾收集器在某个阈值后删除已完成的 Pod(处于 `Succeeded` 或 `Failed` 阶段)。
- 人工干预删除 Job 的 Pod。
- 一个外部控制器(不包含于 Kubernetes)来删除或取代 Pod。
为什么会触发 Pod Gc, 什么时候会触发?
看一下源码 pkg/controller/podgc/doc.go 中的说明
1 | |
简单翻译一下就是,当已结束状态(Failed or Succeeded)的 Pod 的数量 > 配置的值的时候,Pod Gc Controller 就会按照创建时间从远往近开始删除已结束状态的 Pod
后面单独出一篇文章分析 Pod Gc,这里简单看一下 gcTerminated 部分的代码
1 | |
我们可以看到这个删除逻辑也是非常的简单粗暴了,只要超过数量然后就开始删除,但是这个有个问题是,我们现在 terminated pod 数量比 terminatedPodThreshold 这个值大,并且还有 controller 在反复创建 job,这就会导致 pod gc 频繁工作导致 job 一直无法完成了
怎么解决这个问题?
- 最简单的方案就是根据业务的实际需求调整 terminatedPodThreshold 这个值,一般而言默认值 12500 已经足够大了,所以一般也不会触发这个问题,但是需要注意这个值也不能太大,如果太大了,job 有问题可能会直接把 master 打挂
- 但是如果使用云厂商的服务需要注意,我们这次出问题就是因为腾讯云 tke 这个值会根据集群规模自动调整,如果像我们这样集群节点可能不算特别大,也就几百,但是 job 数量特别多就要小心了,这个值比默认值小很多,当时我们是 2000 左右的 pod 就触发了这个问题
- 还有一个办法就是减少 pod 数量
- 这个问题其实在开发阶段出现过,但是当时没发现是 pod gc 的问题,所以我让一个 job 只有 一个 pod,job 关联的父资源状态结束之后,这个 job 就会被删除掉,尽早的去释放到多余的已完成的 pod
- 但是显而易见这个方案治标不治本
- 还有一个方案是 使用 Finalizer 追踪 Job
- k8s 1.22 开始支持 job 给 pod 添加 finalizer,这样可以确保 pod 被意外删除的时候 job controller 可以感知到
- 这个 feature 在 1.22 版本可以手动开启,1.23 版本默认开启,但是 1.24 版本被默认关闭了,因为存在未解决的 bug 可能会导致 job 和 pod 一直处于 terminating 的状态。具体可以看这个 PR
小结
回顾一下这个坑,其实早有预兆,但是机会给了一次次没有及时抓住最后还是跳了下去
- 开发阶段就发现了这个问题,但是不够重视,没有追根溯源,当时解决了就以为解决了
- 测试阶段没有压测,上线前的就已经预料到了最多的时候需要短时间内跑 100W+ 的 job,但是觉得是上线初期感觉压力应该没那么大,把压测时间滞后了
- 生产阶段排查问题没有第一时间去看 k8s 审计以及事件日志,导致走了弯路
最后一个 github 查看源码的 tips,现在只要把 github.com 改成 github.dev 就能直接用 vscode web 版本查看仓库代码,并且还支持代码跳转,文中的所有源码链接都是 github.dev 的链接,可以体验一下
关注我获取更新



猜你喜欢
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处,禁止全文转载