注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
前言 最近 We 川大上的教务处公告新闻已经很久没有更新了,想到可能是 ip 被封了,查了一下 log,发现并不是,而是获取到的页面全变成了混淆过的 js,下面放两个格式化的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 function _$Es (_$Cu ) 14 ] = _$v9();16 )] = _$Dn();var _$cR = _$CR();return _$DA();function _$Dk (_$Cu ) var _$x5 = _$Dv();var _$x5 = _$EB();if (_$Ex()) {16 )] = _$ED();16 )] = _$EP();return _$Cu[_$yf(_$v9(), 16 )];function _$rK (var _$aJ = _$c0(_$DN());2 );var _$Ce = _$yr(_$qt());for (var _$Cu = 0 ; _$Cu < _$aJ[_$gX()]; _$Cu++) {return _$aJ;
看着这一堆就头大,但是本着只要是浏览器能够渲染出来的页面爬虫就可以爬到的原则,一步一步的解决
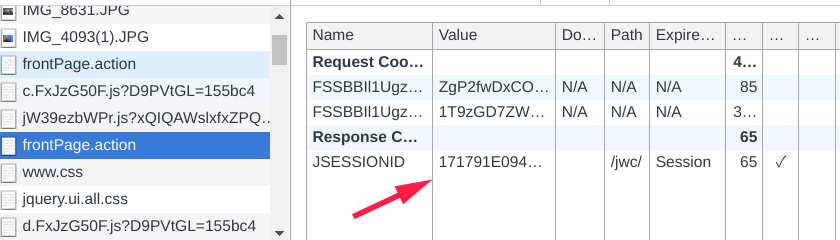
分析 先使用 postman 发送了一下请求,发现返回了上面一堆乱码 复制了正常渲染页面 request header 重新发送请求,可以得到正常的页面。考虑两个可能一个是 header 有什么特殊的处理,一个是 cookie 上的问题。 header 其他内容不变,去掉 cookie 重新发送请求,再一次得到一堆乱码。问题定位成功,应该就是 cookie 的问题了 清空 chrome 的缓存,重新加载页面,查看请求记录,可以看到这个页面一共加载了两次JSESSIONID,这个应该就是最终需要的 cookie 了 观察两次请求的中间,我们可以发现还有两个请求,这两个请求应该就是第二次返回 cookie 的原因了,第一个请求是页面内的外链 js 文件,第二个请求应该就是混淆过的 js 发出的请求了。 因为实力有限,分析了几个小时都没有分析出来这个逻辑是怎么加载的。但是想到了直接从浏览器把 cookie 复制下来给爬虫使用不就可以了?但是这样也还有一个问题,就是不可能每一次都手动的去获取 cookie 这样达不到想要的效果。然后看到 Python 有使用Selenium来完全模拟浏览器渲染然后解析页面的爬虫案例,找了一下 golang 有没有类似的浏览器渲染方案,在万能的 gayhub 上找到了chromedp。下面使用 chromedp 来解决这个问题。 chromedp Package chromedp is a faster, simpler way to drive browsers (Chrome, Edge, Safari, Android, etc) without external dependencies (ie, Selenium, PhantomJS, etc) using the Chrome Debugging Protocol.
1.install(建议使用梯子) 1 go get -u github.com/chromedp/chromedp
2.code 运行下面这一段代码可以看到 chrome 会弹出一个窗口并且运行网页,最后在 console 输出期望的 html,但是我们其实只需要得到正确的 cookie,用来之后爬取网页使用。如果所有的页面都需要等待 chrome 渲染结束之后爬取,那么效率实在是太低了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 package mainimport ("context" "fmt" "io/ioutil" "log" "time" "github.com/chromedp/cdproto/cdp" "github.com/chromedp/chromedp" func main () var err errordefer cancel()if err != nil {var res string `http://jwc.scu.edu.cn/jwc/moreNotice.action` ),`table` , chromedp.ByQuery),"body" , &res),if err != nil {if err != nil {if err != nil {
3.获取 cookie 修改第 2 步当中 task list 的代码获取 cookie,修改之后可以看到 console 当中输出了一段 cookie 字符串,使用这个 cookie 在 postman 当中测试可以发现,可以获取到正确的页面。到了这一步其实就应该算基本完成了,但是还是有一个缺点:每次运行的时候都会弹出一个 chrome 窗口,爬虫在服务器上运行是没有 gui 页面的,并且每次打开一个 chrome 实例的时间开销也比较大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (ctx context.Context, h cdp.Executor) error var c string for _, v := range cookies {"=" + v.Value + ";" if err != nil {return errreturn nil
5.使用 chrome 的 headless 模式 a.使用 docker 运行一个 headless 模式的 chrome
1 docker run -d -p 9222:9222 --rm --name chrome-headless knqz/chrome-headless
b.修改代码
可以看到主要的区别就在创建 chrome 实例的时候没有去启动一个 chrome,当然最后也不需要去关闭它
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 package mainimport ("context" "log" "github.com/chromedp/chromedp/client" "github.com/chromedp/cdproto/network" "github.com/chromedp/cdproto/cdp" "github.com/chromedp/chromedp" func main () var err errordefer cancel()if err != nil {`http://jwc.scu.edu.cn/jwc/moreNotice.action` ),`table` , chromedp.ByQuery),func (ctx context.Context, h cdp.Executor) error var c string for _, v := range cookies {"=" + v.Value + ";" if err != nil {return errreturn nil if err != nil {
到这里基本就可以使用了,获取到 cookie 之后可以使用喜欢的方式去获取页面
关注我获取更新 猜你喜欢